OJ系统使用
输入输出
stdin.readline输入
1 2 3 4 5 6 7 8 9 10 11 12 import systry : while True : line = sys.stdin.readline().strip() if not line: break lines = line.split() print(int(lines[0 ]) + int(lines[1 ])) except : pass
stdin.readlines一次性输入
1 2 3 import syslines=sys.stdin.readlines() print(lines)
list map输入成int
1 2 data=list(map(int,input().split())) print(data)
1 2 3 4 5 6 7 8 9 10 11 12 lines = [] while True : try : str1 = input() if str1 == "" : break lines.append(str1) except : break print(lines) print("," .join(lines))
print()函数控制打印后不换号,而是输出空格
例如:print(x, end=' ') # 使用end参数控制
循环输入带来的调试误区
注意因为循环输入中使用了
except: break导致调试时如果报错运行到了这里直接break,而不是爆出原来的错误,调试的时候应该把这个except去除从而可以暴露出bug!
字符串题
ASCII码
ord()
函数获取字符的Unicode,但是最前面的是ASCII码,因此可以用ord()获得字符的ASCII码。
chr()获取ASCII码对应的字符
1 2 3 4 5 6 7 8 >>> ord('A') 65 >>> ord('中') 20013 >>> chr(66) 'B' >>> chr(25991) '文'
UTF-8 是一种 Unicode
的实现方式。对于英语字母,UTF-8 编码和
ASCII 码是相同的。
前缀后缀
使用startswith() and
endswith() 代替切片进行序列前缀或后缀的检查
比如用if foo.startswith(‘bar’): 会优于
if foo[:3] == ‘bar’:
print('-' *
80)打印一串‘--------------------------------------------------------------------------------‘
字符串计数
写出一个程序,接受一个由字母和数字组成的字符串,和一个字符,然后输出输入字符串中含有该字符的个数。不区分大小写。
1 2 3 line =input().lower() m = input().lower() print( line.count(m))
最大回文字符子串
除了暴力循环判断,也可以使用动态规划算法求解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution : def longestPalindrome (self, s: str) -> str: n = len(s) dp = [[False ] * n for _ in range(n)] ans = "" for l in range(n): for i in range(n): j = i + l if j >= len(s): break if l == 0 : dp[i][j] = True elif l == 1 : dp[i][j] = (s[i] == s[j]) else : dp[i][j] = (dp[i + 1 ][j - 1 ] and s[i] == s[j]) if dp[i][j] and l + 1 > len(ans): ans = s[i:j+1 ] return ans
strip() 和 split() 区别
从英语单词的意义上,
strip: 脱去,去除
split: 分开,分裂
===================================
str.split()) 默认去除所有空格符,包括空格,换行\n, 制表符\t
,即('\n', '\r', '\t', ‘
'),并且返回切割之后的字符串list
str.strip('L')) 移除字符串头和尾
指定的字符(默认为空格或换行符),或给定去除的字符序列,比如此处移除头尾所有L(包括重复L),返回的依然是字符串
另外还有str.rstrip用于删除字符串末尾的空白字符,str.lstrip删除左边的
1 2 3 4 5 6 7 8 9 10 str = "LLLine1-a\tbcdef\nLine2-abc \nLine4-abcddd" print(str.split()) print(str.strip('L' )) >>> ['LLLine1-a' , 'bcdef' , 'Line2-abc' , 'Line4-abcddd' ] >>> ine1-a bcdef Line2-abc Line4-abcddd
1 2 3 4 a = '2135432145e' print(a.split('21' )) >>> ['' , '3543' , '45e' ]
正则模块re.split
re.split模块比str.split()函数强大的多!
我们也可以轻松地指定一个字符范围,像[0-9]代表的含意与\d就是完全一致的:一位数字;同理[a-z0-9A-Z_]也完全等同于\w(如果只考虑英文的话),\w代表
匹配字母或数字或下划线或汉字, \s 匹配任意的空白符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import res = '1,2,3,4,a,5,6,7\n,8,b,9,10,11,12' t=re.split(',[a-c],' , s, flags=re.IGNORECASE) print(t) >>> ['1,2,3,4' , '5,6,7\n,8' , '9,10,11,12' ] y = [x for i in s.split(',a,' ) for x in i.split(',b,' )] print(y) >>> ['1,2,3,4' , '5,6,7\n,8' , '9,10,11,12' ] print(re.split(',[a-b],|\n,|10' , s)) >>> ['1,2,3,4' , '5,6,7' , '8' , '9,' , ',11,12' ] print(re.split('[89b]' , s)) >>> ['1,2,3,4,a,5,6,7\n,' , ',' , ',' , ',10, 11, 12' ]
re模块的re.sub 字符替换功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import res = ' 1,2 3,4,a,5,6,7\n,8,b,9,10, 11, 12 ' print(re.sub("['\"','\'','\s', 9, a, b]" , '' , s)) print(re.sub("['\"''\'','\s'9ab]" , '' , s)) >>> 12345678101112 >>> 12345678101112
数字转换
进制转换函数 int(), hex(), oct()
十六进制 到 十进制
使用 int() 函数
,第一个参数是字符串 '0Xff'
,第二个参数是说明,这个字符串是几进制的数 。
转化的结果是一个十进制数。
>>> int('0xf',16) 15
二进制 到 十进制
>>> int('10100111110',2) 1342
八进制 到 十进制
>>> int('17',8) 15
十进制 转 十六进制
>>> hex(1033) '0x409'
八进制到 十六进制
就是 八进制先转成 十进制, 再转成 十六进制。
>>> hex(int('17',8)) '0xf'
十进制转二进制
>>> bin(10) '0b1010'
十六进制转 二进制
十六进制->十进制->二进制
>>> bin(int('ff',16))
数论题
最大公约数和最小公倍数
判断是否是质数
质数又称素数,指在大于1的自然数中,除了1和该数自身外,无法被其他自然数整除的数(也可定义为只有1与该数本身两个正因数的数)
注意,质数的定义是大于1,所以1不在考虑范围内。2=1*2,只有1和它本身两个因子,所以2是质素。
1 2 3 4 5 6 7 8 9 def isprime (m) : if m == 1 : return False for i in range(2 , int(m**0.5 ) + 1 ): if m % i == 0 : return False return True
更相减损失术和辗转相除法求最大公约数
原理
首先证明更相减损失术:a|b,a|c,则a|(b+c) :
b=a×k(k∈Z),c=a×l(l∈Z) 则,b+c=ak+al=a(k+l),其中k+l∈Z
命题得证。
也就是说gcd(b, c) = gcd(c+b, b) = gcd(c-b, b) = a。
容易看出辗转相除法是更相减损失术的快速计算方法
代码
1 2 3 4 5 6 7 8 9 10 11 def gcd (m, n) : """辗转相除法""" a = max(m, n) b = min(m, n) if a % b == 0 : return b else : return gcd(b, a % b) print(gcd(21 , 28 ))
应用最大公约数求最小公倍数
1 2 3 def min_multiple (m, n) : out = m * n / gcd(m, n) return int(out)
数字拆分,有范围限制
这个问题其实是动态规划章节中【盘子放苹果问题】的变体,参加动态规划章节
这篇博客说的很多
https://cloud.tencent.com/developer/article/1109283,但是下面一个博客更清晰
https://www.cnblogs.com/radiumlrb/p/5797168.html
并且给出了完整代码。
将整数N分成K个整数的和且每个数大于等于A 小于等于B 求有多少种分法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def breakup (number, k, a, b) : if number < a: return 0 if k == 1 : return 1 temp = 0 for i in range(a, b+1 ): temp += breakup(number-i, k-1 , i, b) return temp while True : try : m, k, a, b = map(int, input().split()) t = breakup(m, k, a, b) print(t) except : break
C/C++实现
1 2 3 4 5 6 7 8 9 10 11 12 13 int Dynamics (int n, int k, int min ) if (n < min ) return 0 ; if (k == 1 ) return 1 ; int sum = 0 ; for (int t = min ; t <= B; t++) { sum += Dynamics(n-t, k-1 , t); } return sum; }
其实上述这个问题也可以用“将n划分成不大于m的划分法g(n,
m)”这个问题的解来间接地解决,g(n, b) - g(n, a)
排列组合题
路径走法
请编写一个函数(允许增加子函数),计算n x
m的棋盘格子(n为横向的格子数,m为竖向的格子数)沿着各自边缘线从左上角走到右下角,总共有多少种走法,要求不能走回头路,即:只能往右和往下走,不能往左和往上走。
这个题有两个思路,一个用排列组合的数学角度,一个用递归的角度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def factorial (n) : dot = 1 for i in range(1 ,n+1 ): dot = dot * i return dot while True : try : [n,m] = list(map(int,input().split())) k = factorial(m+n)/(factorial(m)*factorial(n)) print(int(k)) except : break
用递归的角度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def f (n, m) : if m == 1 or n == 1 : return m + n else : return f(n - 1 , m) + f(n, m - 1 ) while True : try : [n, m] = list(map(int, input().split())) out = f(n, m) print(int(out)) except : break
跳台阶
青蛙随意跳
一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
排列组合角度解析:
因为每一步都可以选择跳1~n个台阶,但是最后一个台阶必须跳上,所以一共有
\(2^{n-1}\) 种跳法。
或者通过递推关系式子推导: \[
\begin{equation}
\begin{array}{l}
f(n)=f(n-1)+f(n-2)+\ldots+f(1)+1 \\
=f(n-1)+[f(n-2)+\ldots+f(1)+1] \\
=f(n-1)+f(n-1) \\
=2 * f(n-1) \\
=2 *(n-1)
\end{array}
\end{equation}
\] 递归方法/动态规划角度解析:略
青蛙会两种跳
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级。求该青蛙跳上一个 n
级的台阶总共有多少种跳法
一般递归方法 ,n较大时计算量爆炸,python无法顺利出结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def myjump (n) : if n <= 2 : return 2 return myjump(n-1 ) + myjump(n-2 ) import functools@functools.lru_cache(256) def myjump (n) : if n <= 2 : return 2 return myjump(n-1 ) + myjump(n-2 )
从底向上的想法,更快,不会栈溢出 ,即动态规划方法升级版
1 2 3 4 5 6 7 8 9 10 def hejump (n) : f1 = 1 f2 = 2 sum = 0 for i in range(3 , n+1 ): sum = f1 + f2 f1 = f2 f2 = sum return sum
print(hejump(100)) print(myjump(100))
排序
sorted() 函数
字典排序
使用 sorted()
函数对字典进行排序时,可以先使用d.items() 把字典变成可迭代的对象 ,就变成了
[(key1, value1), (key2, value2)...],
然后再将list中的元组按照第一个元素即key或者第二个value作为排序依据
1 sort_d = sorted(d.items(), key=lambda x: x[0])
sorted()中的key可以接受函数作为参数,此处接受了匿名lambda函数。
注意,字典的key不单单可以是str类型,也可以是int类型 ,但是根据key索引value时类型只能用对应的数据类型,如下面例子
1 2 3 4 myd = {'tom': 2, 4: 5} print(myd.get(4)) # 如果是print(myd.get(‘4’))错误,因为此时的key是int类型 print(myd.get('tom'))
经典排序算法
快排
递归
斐波那契的兔子
有一对兔子,从出生后第3个月起每个月都生一对兔子(雄雌),小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少?
一定要注意处理边界值,所有的不能用递推公式求出的情况都是初始值,比如rabit_num(1)
= abit_num(0) +
abit_num(-1)数组索引为负,这种情况就不能用递推关系式,它应该是初始条件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import functools@functools.lru_cache(maxsize=256) # Least-recently-used cache decorator def rabit_num (n) : if n <= 2 : return 1 return rabit_num(n - 1 ) + rabit_num(n - 2 ) while True : try : m = int(input()) print(rabit_num(m)) except : break
动态规划
动态规划与分治法类似,都是把大问题拆分成小问题,通过寻找大问题与小问题的递推关系 ,解决一个个小问题,最终达到解决原问题的效果。但不同的是,分治法在子问题和子子问题等上被重复计算了很多次,而动态规划则具有记忆性,通过填写表 把所有已经解决的子问题答案纪录下来,在新问题里需要用到的子问题可以直接提取,避免了重复计算,从而节约了时间,所以在问题满足最优性原理之后,用动态规划解决问题的核心就在于填表,表填写完毕,最优解也就找到。
二维数组的动态规划
定义数组元素的含义;找出数组元素间的关系;找出初始值
搞清楚数组元素的含义,求解问题时一定要明确,我们的目标是把大问题分解成若干子问题来求解! 领悟套路解题套路:https://zhuanlan.zhihu.com/p/91582909
盘子放苹果
题目描述
把M个同样的苹果放在N个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法?(用K表示)5,1,1和1,5,1
是同一种分法。
输入
每个用例包含二个整数M和N。0<=m<=10,1<=n<=10。
递归解法
对于下面递归出口的说明
当n=1时,所有苹果都必须放在一个盘子里,所以返回1;
当没有苹果可放时,定义为1种放法;
递归的两条路,第一条n会逐渐减少,终会到达出口n==1;
第二条m会逐渐减少,因为n>m时,我们会return
count(m,m) 所以终会到达出口m==0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def count (m,n) : if m==0 or n==1 : return 1 if m<n: return count(m,m) else : return count(m,n-1 )+count(m-n,n) while True : try : l=input().split() m=int(l[0 ]) n=int(l[1 ]) print(count(m,n)) except : break
动态规划解法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def put_apple (m, n) : dp = [[0 for i in range(n + 1 )] for j in range(m + 1 )] for j in range(1 , n + 1 ): dp[1 ][j] = 1 for j in range(1 , n + 1 ): dp[0 ][j] = 1 for i in range(1 , m + 1 ): dp[i][1 ] = 1 for i in range(2 , m + 1 ): for j in range(2 , n + 1 ): if i < j: dp[i][j] = dp[i][i] else : dp[i][j] = dp[i][j - 1 ] + dp[i - j][j] return dp[m][n] while True : try : m, n = map(int, input().split()) t = put_apple(m, n) print(t) except : break
如果题目变成不能有空盘子,那么我们仍然可以利用上面的代码,只是调用上面函数时变成count(m-n,
n)即可,先每个盘子放一个苹果,其他的可以随便放,允许有空盘子。
同时上面这个问题和下面这个问题等价:
正整数划分 或
没有空盘子的放苹果
把数字M划分成K个正整数和,有多少种划分方法?
设dp [i] [j]代表把数字 i 划分成 j
个正整数的划分方法数,则这件事可以分解为两个子问题:至少 有一个盘子放了一个1;所有的盘子放的数全部都大于1。那么dp[i]
[j] = dp[i-1] [j-1] +dp[i-j] [j]。
第二项正确的保障是根据我们对数组元素的定义来的 ,因为dp
[i] [j] 表示每个盘子至少放1个苹果不能有空盘
(等价于分解数全部为正整数),所以我们先每个盘子放一个1,这样就保证剩下的苹果放入的时候dp[i-j]
[j] 每个盘子又至少放了一个1.
动态规划解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def breakup (m, n) : dp = [[0 for i in range(n + 1 )] for j in range(m + 1 )] for j in range(1 , n + 1 ): dp[0 ][j] = 1 for i in range(1 , m + 1 ): dp[i][1 ] = 1 for i in range(1 , m + 1 ): for j in range(1 , n + 1 ): if i < j: continue elif j == i: dp[i][j] = 1 else : dp[i][j] = dp[i-1 ][j-1 ] + dp[i-j][j] return dp[m][n] while True : try : m, k = map(int, input().split()) t = breakup(m, k) print(t) except : break
正整数划分,要求划分出来的每个数都不大于k
整数m划分成最大数不超过n的若干整数之和的方案数
这个问题当n==m时就变成了“整数m划分成若干正整数之和的方案数”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def put_apple (m, n) : dp = [[0 for i in range(n + 1 )] for j in range(m + 1 )] for j in range(1 , n + 1 ): dp[0 ][j] = 1 for i in range(1 , m + 1 ): dp[i][1 ] = 1 for j in range(1 , n + 1 ): dp[1 ][j] = 1 for i in range(2 , m + 1 ): for j in range(2 , n + 1 ): if i < j: dp[i][j] = dp[i][i] else : dp[i][j] = dp[i - j][j] + dp[i][j - 1 ] return dp[m][n] while True : try : a, b = map(int, input().split()) t = put_apple(a, b) print(t) except : break
从代码角度来看,和“把M个同样的苹果放在N个同样的盘子里,允许有的盘子空着不放”貌似是等价的
正整数划分,要求划分出来的每个数不能相同
将n划分为若干个不同的正整数 ,注意:划分数不同
这一题仍然可以参考上面的代码,在上一题如果k=m,则就是划分数可以相同时的方案数目 ,只需要k设成这个数本身即可。设dp[i]
[j]
表示把数字i划分成划分数不超过j的方案数,因此来找子问题。至少略有区别:
分析:
1 2 3 4 5 dp[n][m]= dp[n][m-1]+ dp[n-m][m-1] 其中dp[n][m]表示整数 n 划分成不同划分数的方案数,且每个划分数不大于 m。 同样划分情况分为两种情况: a.划分中每个数都小于m,相当于每个数不大于 m-1,划分数为 dp[n][m-1]. b.划分中有一个数为 m.在n中减去m,剩下相当对n-m进行划分,并且每一个数不大于m-1 (因为题目要求不能有相同数,所以剩下的划分不能再有m),故划分数为 dp[n-m][m-1]
把数字n划分成若干个奇数/偶数的方案数
解法有些特殊,构造了两个二维数组,设f[i][j]表示将数i分成j个正奇数,g[i][j]表示将数i分成
j 个正偶数。这里没有限制划分成多少个,那么可能划分成1,2, 3,...,
n个奇数,那么答案就是 f[i][j]把j从1开始遍历到n相加.
https://blog.csdn.net/qq_40691051/article/details/103216117
f[i][j]和g[i][j]之间是有关系的,如果我们先从被划分的数
i 中拿出 j 个1,然后把剩下的 i - j 分解成 j
个正奇数的方案数应该和将数i分成 j 个正偶数的方案数相同,即
g[i][j] = f[i-j][j]
f[i][j]可以分解成划分数包含1(即至少一个1)和不包含1这两个子问题,那么有
f[i][j]=f[i-1][j] + g[i-j][j];
其中前者是在奇数划分时先拿出一个1保证至少划分数里有一个1,后者是偶数划分时先拿出j个1放入,这样保证之后划分数每个都会大于1(得益于f[i][j]数组元素的定义)
最后
f[n][m]即为所求 。边界条件还没弄清,下面代码没有经过充分测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 n, k = list(map(int, input().split())) f = [[0 ] * (n+1 ) for i in range(n+1 )] g = [[0 ] * (n+1 ) for i in range(n+1 )] for i in range(n+1 ): f[i][i] = 1 g[2 ][1 ] = 1 for i in range(3 , n+1 ): for j in range(1 , i): g[i][j] = f[i-j][j] f[i][j] = f[i-1 ][j-1 ] + g[i-j][j] print(f[n][k]) res = sum(f[n]) print(res)
棋盘格通过路径的数字之和
给定一个包含非负整数的 m x n
网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小(经过的路径途中的单元格上的数字的和)。
1 2 3 4 5 6 7 8 9 举例:arr存储了m*n网格中每个单元上的数字 输入: arr = [ [1 ,3 ,1 ], [1 ,5 ,1 ], [4 ,2 ,1 ] ] 输出: 7 解释: 因为路径 1 →3 →1 →1 →1 的总和最小。
解法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from typing import Listarr = [ [1 , 3 , 1 ], [1 , 5 , 1 ], [4 , 2 , 1 ] ] def minPathSum (grid: List[List[int]]) -> int: for i in range(len(grid)): for j in range(len(grid[0 ])): if i == j == 0 : continue elif i == 0 : grid[i][j] = grid[i][j - 1 ] + grid[i][j] elif j == 0 : grid[i][j] = grid[i - 1 ][j] + grid[i][j] else : grid[i][j] = min(grid[i - 1 ][j], grid[i][j - 1 ]) + grid[i][j] return grid[-1 ][-1 ] t = minPathSum(arr) print(t)
编辑距离
问题描述: 给定两个单词 word1 和 word2,计算出将 word1 转换成 word2
所使用的最少操作数 。 你可以对一个单词进行如下三种操作: ---插入一个字符
---删除一个字符 ---替换一个字符
解答
定义数组元素的含义,这一步看似简单其实对于问题的建模理解非常重要
dp[i][j] 代表着word1的前 i
个字符 转换成word2的前 j
个字符 所需要的最少操作步数,那么就出现了二维数组问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def minDistance (word1: str, word2: str) -> int: n1 = len(word1) n2 = len(word2) dp = [[0 ] * (n2 + 1 ) for _ in range(n1 + 1 )] for j in range(1 , n2 + 1 ): dp[0 ][j] = dp[0 ][j-1 ] + 1 for i in range(1 , n1 + 1 ): dp[i][0 ] = dp[i-1 ][0 ] + 1 for i in range(1 , n1 + 1 ): for j in range(1 , n2 + 1 ): if word1[i-1 ] == word2[j-1 ]: dp[i][j] = dp[i-1 ][j-1 ] else : dp[i][j] = min(dp[i][j-1 ], dp[i-1 ][j], dp[i-1 ][j-1 ]) + 1 return dp[-1 ][-1 ] t = minDistance('iamoksklal' , 'thmsklat' ) print(t)
完全背包问题
非常好的一个讲解博客:https://www.cnblogs.com/christal-r/p/dynamic_programming.html
有n
个物品,它们有各自的重量和价值,现有给定容量的背包,如何让背包里装入的物品具有最大的价值总和?
定义状态变量(使用的数组元素的意义)V(i, j)
为当前包的容量为 j (也就是已经挑选的物品总重量不超过 j ),已经决策了前
i
个物品是否放入后的最佳策略所对应的价值 。如果还不明白这个含义,那换一句表述:该状态变量表示在前
i 件物品中选择若干件放在可用容量为 j
的背包中(这个背包的容量指的是我们使用的背包最大容量,不一定把包装满 ),可以取得的最大价值。
求解
设包的最大容量为C,每一件物品的重量为 \(w_{i}\) ,其价值为 \(p_{i}\) ,下面寻找状态转移方程。对于当前第
i 个物品,我们决策是否应该把它放进包里,只有两种可能:
包的容量小于该物品的重量 \(j<w_{i}\) ,此物品不能放入包。则此时对前
i 个物品处理的最佳策略对应的价值和前 i-1 个物品和包容量为 j
的决策结果的最优值相同,即 \(\ V(i, j)= V(i-1,
j)\)
包的容量大于当前物品重量 \(j>=w_{i}\)
,包可以放下此物品。根据我们定义的状态变量V(i, j)
的含义,当包容量为j时,最优策略可能并没有放入第i个物品,即不一定非要把包全部填满才能达到价值最大。 那么对于第i个物品,我们有两种可能的决策,放入和不放入。也就是说
$ V(i,j)$ 这个问题显然和 $ V(i-1, j-w_{i})$ 和 $ V(i-1, j)$
这两个子问题有关 。不要忘记动态规划其实就是在逐步填写表,表填完了,最优解也就得到了。
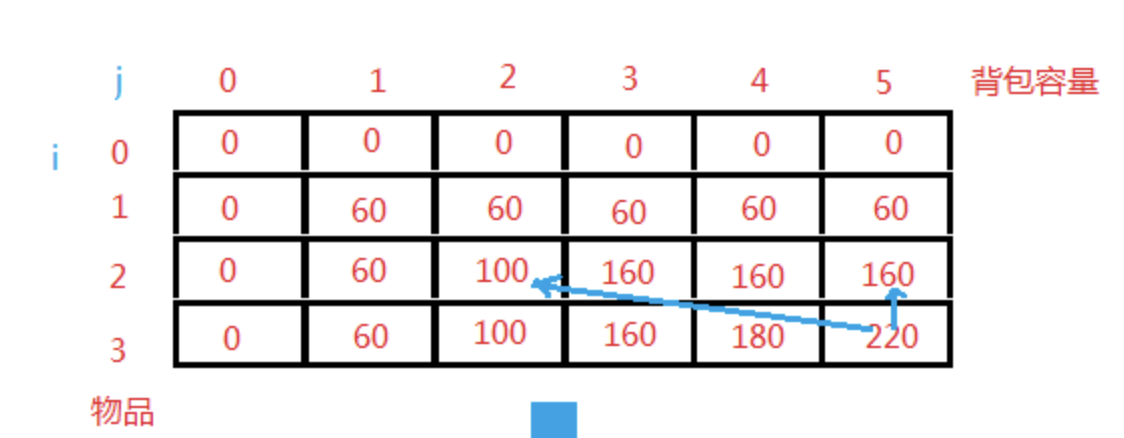
例如下图中,我们有3种物品,他们的重量和价格分别是1, 2, 3 kg和60, 100,
120,而包的最大容量为5。
不放入当前的第 i 个商品的话 \(V(i, j)=
V(i-1, j)\) ;
放入当前第 i 个商品的话 \(V(i, j)=
V(i-1, j)+p_{i}\) 。
那么我们选择当前两种决策中最优的那个,即 $ V(i, j)= max(V(i-1, j),
V(i-1, j-w_{i})+p_{i})$ 。而只有当 \(V(i, j)=
V(i-1, j-w_{i})+p_{i}\) 时,才有“取第 i 件物品”发生。
现在我们知道了最大价值,但还不知道由哪些商品组成,故要根据最优解回溯解的构成。
回溯
根据我们填表的过程可以方向得出我们取了哪些物品,回溯的算法描述摘录自上面的博客链接。
V(i,j)=V(i-1,j)时,说明没有选择第i
个商品,则回到V(i-1,j);
V(i,j)=V(i-1,j-w(i))+p(i)实时,说明装了第i个商品,该商品是最优解组成的一部分,随后我们得回到装该商品之前的最优策略对应的解,即回到V(i-1,j-w(i));
一直遍历到i=0结束为止,所有解的组成都会找到。
代码:
一维数组的动态规划
剪绳子
给你一根长度为n的绳子,请把绳子剪成m段(m、n都是整数,n>1并且m>1),每一段的长度记为k[0],k[1],...k[m].请问k[0]xk[1]x...xk[m]可能
的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18.
解析:这个问题和前面的背包问题有些不同,背包问题分解的子问题之和以前的解以及当前物品的决策有关。而剪绳子不光与之前切割过的绳子结果有关,剩余部分的绳子切割方式会一起决定切割分段的乘积结果。如果是利用动态规划的方式去做,我们考虑对于一个长度为n的绳子,假设切分后的最大乘积为f(n),我们先来考虑第一刀,长度为n的绳子把它切成长度为i和n-i的两段(因为由题意至少切割一次),这两段各自的绳子切分最大值为f(i)和f(n-i),如此一来就找了子问题分解,即
f(n) = max{f(i), f(n-i)}, 其中 1 <= i <=n-1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def cutRope (number) : if number <= 3 : return number - 1 prod = [0 , 1 , 2 , 3 ] for i in range(4 , number + 1 ): max = 0 for j in range(1 , i // 2 + 1 ): pro = prod[j] * prod[i - j] if pro > max: max = pro prod.append(max) return prod[number] print(cutRope(6 ))
当然了,这道题也可以通过贪心的策略来解答
https://blog.csdn.net/lc199408/article/details/80929108
最长上升子序列 (LIS)
举个例子:求A={2 7 1 5 6 4 3 8 9}的最长上升子序列。我们定义d(i)
(i∈[1,n])来表示前i个数以A[i]结尾的最长上升子序列长度。
https://blog.csdn.net/lxt_Lucia/article/details/81206439
1 2 3 4 5 6 7 8 9 10 11 12 alist = [2 , 7 , 1 , 5 , 6 , 4 , 3 , 8 , 9 ] dp = [1 for i in range(len(alist))] for i in range(1 , len(alist)): for j in range(0 , i): if alist[i] > alist[j]: dp[i] = max(dp[j] + 1 , dp[i]) LIS_len = max(dp) print(LIS_len)
DFS 和 BFS
图的遍历基础实现
忘记在哪里看到的模板了.... 想起了再添加链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 from collections import deque import sysfrom typing import Listclass Graph (object) : def __init__ (self, *args, **kwargs) : self.order = [] self.neighbor = {} def add_node (self, node) : """适用于给出一个顶点和与之相邻的所有顶点是list数据结构""" key, val = node if not isinstance(val, list): print('node value should be a list' ) self.neighbor[key] = val def add_edges (self, n, edges: List[List[int]]) : """适用于给出图的顶点数目以及图中存在的所有边的数据结构""" if not isinstance(edges[0 ], list): print('edges value should be a list' ) for i in range(n): self.neighbor[i] = [] for _edge in edges: self.neighbor[_edge[0 ]].append(_edge[1 ]) self.neighbor[_edge[1 ]].append(_edge[0 ]) def breadth_first (self, root) : if root != None : search_queue = deque() search_queue.append(root) visited = [] else : print('root is None' ) return -1 while search_queue: person = search_queue.popleft() if person not in self.order: self.order.append(person) if (not person in visited) and (person in self.neighbor.keys()): search_queue += self.neighbor[person] visited.append(person) def depth_first (self, root) : if root != None : search_queue = deque() search_queue.append(root) visited = [] else : print('root is None' ) return -1 while search_queue: person = search_queue.popleft() if person not in self.order: self.order.append(person) if (not person in visited) and (person in self.neighbor.keys()): tmp = self.neighbor[person] tmp.reverse() for index in tmp: search_queue.appendleft(index) visited.append(person) def clear (self) : self.order = [] def node_print (self) : for index in self.order: print(index, end=' ' ) if __name__ == '__main__' : g = Graph() g.add_node(('1_key' , ['one_key' , '2' , '3' ])) g.add_node(('one_key' , ['first_key' , 'two' , 'three' ])) g.add_node(('first_key' , ['1' , 'second' , 'third' , '1_key' ])) g.breadth_first('1_key' ) print('breadth search first:' ) print(' ' , end=' ' ) g.node_print() g.clear() print('\n\ndepth search first:' ) print(' ' , end=' ' ) g.depth_first('1_key' ) g.node_print() print()
二叉树的遍历
https://leetcode-cn.com/problems/binary-tree-inorder-traversal/solution/die-dai-he-di-gui-by-powcai
中序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution : def inorderTraversal (self, root: TreeNode) -> List[int]: def helper (node) : if not node: return [] helper(node.left) ann.append(node.val) helper(node.right) ann = [] helper(root) return ann
验证二叉树搜索
https://leetcode-cn.com/problems/validate-binary-search-tree/
读取列表为二叉树
若干典型例题
无环无向图连通分量的数目
如果使用上述基础实现,可以怎么做:
1 2 3 4 5 6 7 8 9 10 11 12 gg = Graph() n = 5 edges = [[0 , 1 ], [1 , 2 ], [2 , 3 ], [3 , 4 ]] gg.add_edges(n, edges) res = 0 for i in range(n): if i not in gg.order: res += 1 gg.depth_first(i) print(res)
岛屿的数量
给你一个由 '1'(陆地)和
'0'(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向或竖直方向上相邻的陆地连接形成。每座岛屿只能由水平和/或竖直方向上相邻的陆地连接而成。
输入: [ ['1','1','1','1','0'], ['1','1','0','1','0'],
['1','1','0','0','0'], ['0','0','0','0','0']] 输出: 1
输入: [ ['1','1','0','0','0'], ['1','1','0','0','0'],
['0','0','1','0','0'], ['0','0','0','1','1']] 输出: 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from typing import Listclass Solution : def numIslands (self, grid: List[List[str]]) -> int: if not grid: return 0 row = len(grid) col = len(grid[0 ]) cnt = 0 def dfs (i, j) : """ 如何避免在方格中的重复遍历呢?答案是标记已经遍历过的格子。以岛屿问题为例, 我们需要在所有值为 1 的陆地格子上做 DFS 遍历。每走过一个陆地格子, 就把格子的值改为 2,这样当我们遇到 2 的时候,就知道这是遍历过的格子了。 也就是说,每个格子可能取三个值: 0 —— 海洋格子 1 —— 陆地格子(未遍历过) 2 —— 陆地格子(已遍历过) 链接:https://leetcode-cn.com/problems/number-of-islands/solution/dao-yu-lei-wen-ti-de-tong-yong-jie-fa-dfs-bian-li-/ """ grid[i][j] = "2" for x, y in [[-1 , 0 ], [1 , 0 ], [0 , -1 ], [0 , 1 ]]: tmp_i = i + x tmp_j = j + y if 0 <= tmp_i < row and 0 <= tmp_j < col and grid[tmp_i][tmp_j] == "1" : dfs(tmp_i, tmp_j) for i in range(row): for j in range(col): if grid[i][j] == "1" : dfs(i, j) cnt += 1 return cnt
所有岛屿中面积最大的那个
题解:https://leetcode-cn.com/problems/max-area-of-island/solution/
是上一个问题的变体,记录下每个连通区域的面积即可,但是注意#
python的形式参数传入过程有坑,数字对象不允许引用,只有可变数据结构才允许引用直接修改原始值,详情可见:
http://www.ityouknow.com/python/2020/01/07/python-function_parameter-112.html
所有岛屿中,周长最大的那个
输入: [[0,1,0,0], [1,1,1,0], [0,1,0,0], [1,1,0,0]]
输出: 16
解释: 它的周长是下面图片中的 16 个黄色的边:
分析 :如果岛屿cell和水(0)相邻或者和边界相邻,那么就会多出一条边
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from typing import Listclass Solution : def __init__ (self) : self.current_area = 0 def islandPerimeter (self, grid: List[List[int]]) -> int: if not grid: return 0 row = len(grid) col = len(grid[0 ]) cnt = 0 max_perimenter = 0 def dfs (i, j) : grid[i][j] = 2 for x, y in [[-1 , 0 ], [1 , 0 ], [0 , -1 ], [0 , 1 ]]: tmp_i = i + x tmp_j = j + y if 0 <= tmp_i < row and 0 <= tmp_j < col and grid[tmp_i][tmp_j] == 1 : dfs(tmp_i, tmp_j) if tmp_i >= row or tmp_i < 0 : self.current_area += 1 if tmp_j < 0 or tmp_j >= col: self.current_area += 1 if 0 <= tmp_i < row and 0 <= tmp_j < col and grid[tmp_i][tmp_j] == 0 : self.current_area += 1 for i in range(row): for j in range(col): if grid[i][j] == 1 : self.current_area = 0 dfs(i, j) cnt += 1 max_perimenter = max(max_perimenter, self.current_area) return max_perimenter s = Solution() arr=[[0 ,1 ]] res=s.islandPerimeter(arr) print(res)
朋友圈
链接:https://leetcode-cn.com/problems/friend-circles
班上有 N
名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A
是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C
的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] =
1,表示已知第 i 个和 j
个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
例如输入: [[1,1,0], [1,1,0], [0,0,1]] 输出:2 解释:已知学生 0
和学生 1 互为朋友,他们在一个朋友圈。
第2个学生自己在一个朋友圈。所以返回 2 。
分析 :把寻找岛屿个数代码稍稍修改一下即可,只是此时遍历应该是逐行遍历,而不是上下左右四个位置了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from typing import Listclass Solution : def findCircleNum (self, M: List[List[int]]) -> int: grid = M if not grid: return 0 row = len(grid) col = len(grid[0 ]) cnt = 0 def dfs (i, j) : grid[i][j] = 2 for y in range(col): tmp_i = i tmp_j = y if grid[tmp_i][tmp_j] == 1 : grid[tmp_i][tmp_j] = 2 dfs(tmp_j, tmp_i) for i in range(row): for j in range(col): if grid[i][j] == 1 : dfs(i, j) cnt += 1 return cnt arr = [[1 , 1 , 0 ], [1 , 1 , 0 ], [0 , 0 , 1 ]] s = Solution() res = s.findCircleNum(arr) print(arr) print(res)
小知识
lambda函数
lambda函数也叫匿名函数,即没有具体名称的函数,它允许快速定义单行函数,类似于C语言的宏,可以用在任何需要函数的地方。这区别于def定义的函数。
lambda函数有一些应用,但常常可以被普通函数取代,例如下面的可以点定义def
mutiply_2(x): return x * 2然后用mutiply_2 取代lambda x: x*2
缓存中间结果用来加速计算
使用python中的lru_cache
1 2 3 4 import functools # 下面这个装饰器用来换成中间结果,用于重复计算时的加速 @functools.lru_cache(maxsize=256) # Least-recently-used cache decorator