摘录自:
https://zhuanlan.zhihu.com/p/35356992
https://zhuanlan.zhihu.com/p/29360425
正则化理解之结构最小化
首先给出一个例子解释L1的作用可以使得模型获得稀疏解
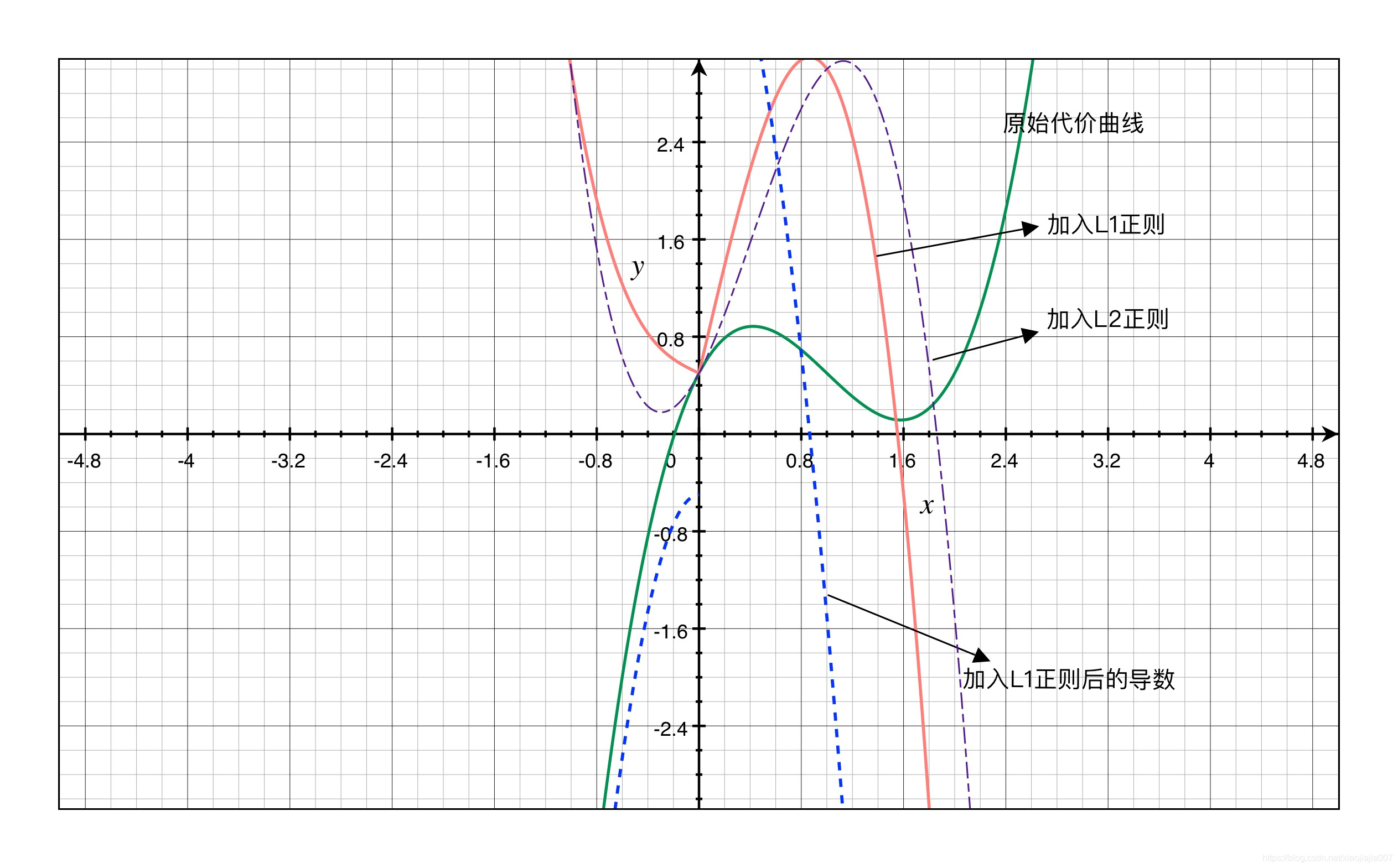
正则化之所以能够降低过拟合的原因在于,正则化是结构风险最小化的一种策略实现。
给loss function加上正则化项,能使得新得到的优化目标函数h = f+normal,需要在f和normal中做一个权衡(trade-off),如果还像原来只优化f的情况下,那可能得到一组解比较复杂,使得正则项normal比较大,那么h就不是最优的,因此可以看出加正则项能让解更加简单,符合奥卡姆剃刀理论,同时也比较符合在偏差和方差(方差表示模型的复杂度)分析中,通过降低模型复杂度,得到更小的泛化误差,降低过拟合程度。
L1正则化和L2正则化:
L1正则化就是在loss function后边所加正则项为L1范数,加上L1范数容易得到稀疏解(0比较多)。L2正则化就是loss function后边所加正则项为L2范数的平方,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于0(但不是等于0,所以相对平滑)的维度比较多,降低模型的复杂度。
作图说明
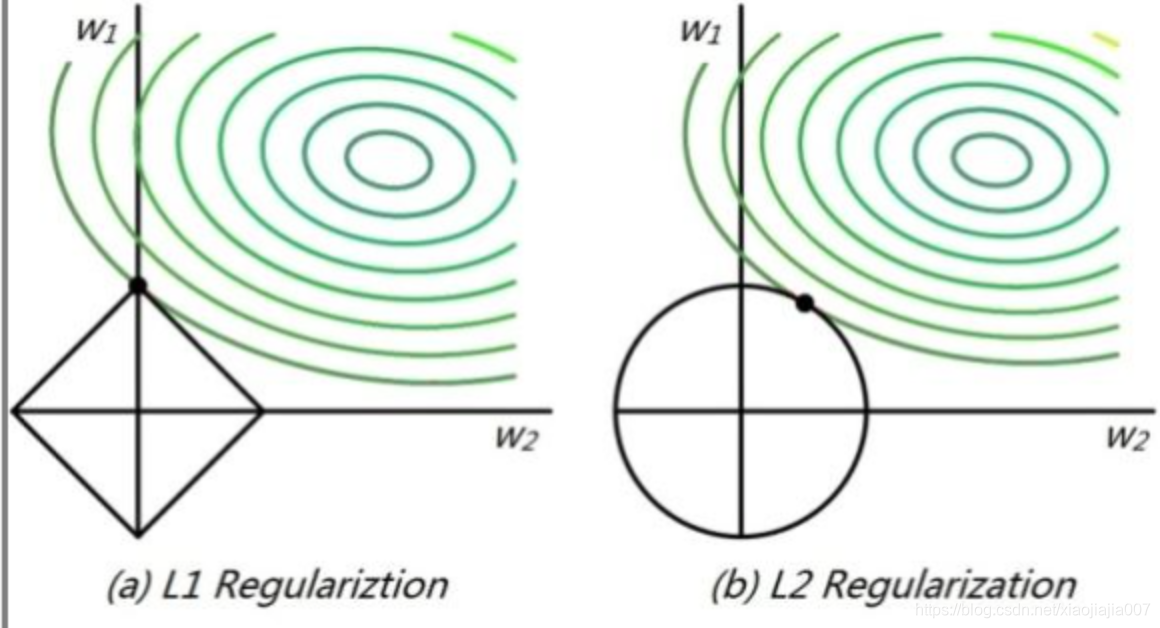 从等高线和取值空间的交点可以看到L1更容易倾向一个权重偏大一个权重为0。L2更容易倾向权重都较小。
从等高线和取值空间的交点可以看到L1更容易倾向一个权重偏大一个权重为0。L2更容易倾向权重都较小。
而通过求导数可以看出,对于两种正则带来的梯度更新:
- L1减少的是一个常量,L2减少的是权重的固定比例
- 孰快孰慢取决于权重本身的大小,权重刚大时可能L2快,较小时L1快
- L1使权重稀疏,L2使权重平滑,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0
正则化理解之最大后验概率估计(MAP)
在最大似然估计中1
设\(X\) 、 \(y\) 为训练样本和相应的标签, \(X=\left(x_{1}, x_{2}, \ldots, x_{n} \right)\) 是一组抽样数据,满足独立同分布假设(i.i.d),假设权重 \(w\) 是未知的参数,从而求得对数似然函数,然后找到使得MLP在当前观测到的数据集条件下达到最大值时对应的权重\(w\): \[ \operatorname{MLP}=l(w)=\log [P(y | X ; w)]=\log \left[\prod_{i} P\left(y^{i} | x^{i} ; w\right)\right] \] 通过假设 \(y^{i}\) 的不同概率分布,即可得到不同的模型(即变成已知模型形式,拟合模型参数的问题,w的写法是前面加分号,表示它是某一固定参数值,而不是概率条件!)。例如若假设 \(y^{i} \sim N\left(w^{T} x^{i}, \sigma^{2}\right)\) 的高斯分布(\(x^{i}\)也是一系列随机向量,随机向量的每个分量都对\(y^{i}\)有影响,若随机向量的维度很大,可以认为\(y^{i}\)服从正态分布,而一般正态分布可以转化成标准正态分布求解),则有: \[ l(w)=\log \left[\prod_{i} \frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{\left(y^{i}-w^{T} x^{i}\right)^{2}}{2 \sigma^{2}}}\right]=-\frac{1}{2 \sigma^{2}} \sum_{i}\left(y^{i}-w^{T} x^{i}\right)^{2}+C \] 式子中\(C\)是常数项,常数项和系数项不影响求最大值,因而可令\(J(w ; X, y)=-l(w)\)即可得到线性回归的代价函数。这里我们可以看到,假设\(y^{i}\) 服从正态分布的极大似然估计方法和均方误差最小化求解线性回归的结果是一样的!
在最大后验概率估计中
将权重\(w\)看作随机变量,也具有某种分布,从而有: \[ P(w|X,y)=\frac { P(w,X,y) }{ P(X,y) } =\frac { P(X,y|w)P(w) }{ P(X,y) } =\frac { P(X)P(y|w,X)P(w) }{ P(X,y) } \propto P(y|X,w)P(w) \] 上面式子中\(P(X,y)\)等对于特定问题已经是固定值了,与\(w\)无关,所以求的\(P(w|X,y)\)正比于\(P(y|X,w)P(w)\)。 那我们利用最大后验概率估计求参数 \(w\) 的时候,找到使得MAP在当前观测到的数据集条件下达到最大值时对应的权重\(w\)。同样取对数有2 3: \[ \operatorname{MAP}=\log P(y | X, w) P(w)=\log P(y | X, w)+\log P(w) \] 可以看出后验概率函数为在似然函数的基础上增加了一项 \(\log P(w)\)。\(P(w)\)的意义是对权重系数\(w\)的概率分布的先验假设,在收集到训练样本{\(X,y\)}后,则可根据w在{\(X,y\)}下的后验概率对\(w\)进行修正,从而可以对\(w\)更好地估计。
这里补充一下周志华老师的西瓜书149页的知识:
概率学派认为参数虽然未知,但确实是客观存在的固定值,而贝叶斯学派则认为参数是未观察到的随机变量,其本身也有分布。因此可以先假定参数服从某个先验分布(没有观测到任何当前的数据前的先验知识),然后基于当前的观测值来计算参数的后验分布。
若假设 \(w_{j}\) 的先验分布为0均值的高斯分布,即 \(w_{j} \sim N\left(0, \sigma^{2}\right)\),
则有: \[
\log P(w)=\log \prod_{j} P\left(w_{j}\right)=\log
\prod_{j}\left[\frac{1}{\sqrt{2 \pi} \sigma}
e^{-\frac{\left(w_{j}\right)^{2}}{2 \sigma^{2}}}\right]=-\frac{1}{2
\sigma^{2}} \sum_{j} w_{j}^{2}+C^{\prime}
\] 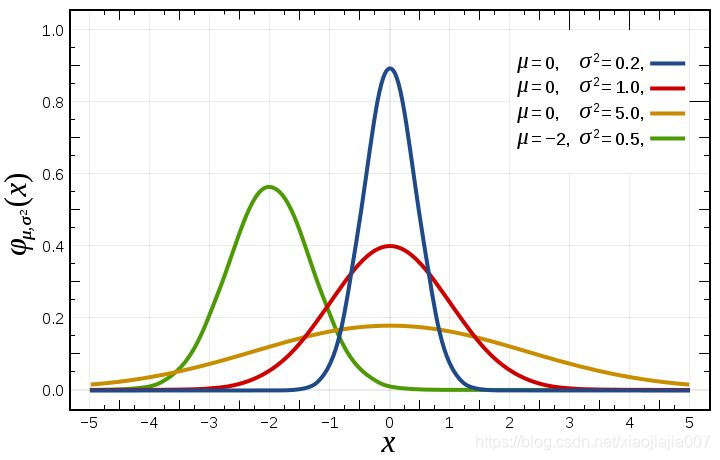 可以看到,在高斯分布下\(\log{P(w)}\)的效果等价于在代价函数中增加\(L_{2}\)正则项,也就是说在MAP中使用一个高斯分布的先验等价于在MLE中采用L2的正则。从上图可以看出\(w\)值取到0附近的概率特别大。也就是说我们提前先假设了\(w\)的解更容易取到0的附近。
可以看到,在高斯分布下\(\log{P(w)}\)的效果等价于在代价函数中增加\(L_{2}\)正则项,也就是说在MAP中使用一个高斯分布的先验等价于在MLE中采用L2的正则。从上图可以看出\(w\)值取到0附近的概率特别大。也就是说我们提前先假设了\(w\)的解更容易取到0的附近。
若假设\(w_{j}\)服从均值为0、参数为a的拉普拉斯分布,即:\(P\left(w_{j}\right)=\frac{1}{2 a} e^{\frac{-\left|w_{j}\right|}{a}}\)
则有: \[
\log P(w)=\log \prod_{j} \frac{1}{2 a}
e^{\frac{-\left|w_{j}\right|}{a}}=-\frac{1}{a}
\sum_{j}\left|w_{j}\right|+C^{\prime}
\] 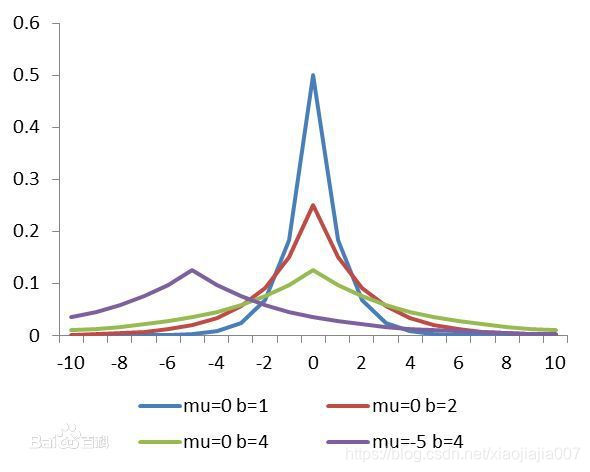 可以看到,在拉普拉斯分布下\(\log{P(w)}\)的效果等价于在代价函数中增加\(L_{1}\)正则项。从下图可以看出\(w\)值取到0的概率特别大。也就是说我们提前先假设了\(w\)的解更容易取到0。
可以看到,在拉普拉斯分布下\(\log{P(w)}\)的效果等价于在代价函数中增加\(L_{1}\)正则项。从下图可以看出\(w\)值取到0的概率特别大。也就是说我们提前先假设了\(w\)的解更容易取到0。
我们得到对于\(L_{1}\)、\(L_{2}\)正则化的一种最大后验角度理解
- \(L_{1}\)正则化可通过假设权重\(w\) 的先验分布为拉普拉斯分布,由最大后验概率估计导出
- \(L_{2}\)正则化可通过假设权重\(w\) 的先验分布为高斯分布,由最大后验概率估计导出

