说在前面:在多模态学习项目中,只要把自然语言(即文本数据)和音频信号(即一维时序数据,脑电、皮肤电等生理信号可类比处理)预处理成深度模型能够接受为输入的数字格式后,剩下的技术部分(尤其是对于Transformer这种天生适用于多模态数据处理的深度模型)和CV项目遇到的内容几乎一样,大家很快便能上手。
自然语言处理基础
术语辨析
text embedding, word embedding, sentence embedding, linguistic embedding概念辨析
-- ChatGPT回答 -- 在描述BERT等语言模型时,应该使用"word embedding"(词嵌入)和"sentence embedding"(句子嵌入)这两个术语来准确地表达。这两个术语更符合描述BERT等模型输出的内容。
- Word Embedding(词嵌入): BERT等模型的输出是每个单词的上下文相关的词嵌入。每个词都被嵌入到一个高维空间中,这个嵌入向量包含了单词的语义信息。这个过程被称为"word embedding",因为它将单词映射到一个向量空间中。
- Sentence Embedding(句子嵌入): BERT等模型的输出也可以用于生成整个句子的嵌入向量,用于表示句子的语义信息。这个过程被称为"sentence embedding",因为它将整个句子嵌入到一个向量空间中。
- "Text embedding"(文本嵌入) 是一个更广义的术语,可以包括词嵌入和句子嵌入,但在描述BERT等特定的语言模型时,使用"word embedding"和"sentence embedding"会更具体和准确。
- "linguistic embedding"(语言嵌入) 是一个相对较宽泛的术语,可能会包括不仅仅是词和句子,还可能包括更高级的语言单元,如短语、段落等。
linguistic, verbal, text,language,lexical单词辨析
-- ChatGPT回答 --
- Linguistic, adj:
- 一般使用场景: 用于描述与语言学相关的特性,例如语法、语义等。
- 多模态情感分析: 在这个领域,主要用于分析文本中的语言学特征,如情感词汇、语法结构等。
- Verbal, adj:
- 一般使用场景: 强调与用言语表达的有关。
- 多模态情感分析: 主要用于描述通过口头言语传达的情感,注重言辞和措辞中的情感。
- Text, n,形容词形式是 "textual":
- 一般使用场景: 指书面语言的形式。
- 多模态情感分析: 用于描述书面语言,强调在文本中表达的情感,适用于文本情感分析。
- Language, n:
- 一般使用场景: 指人类沟通的工具,包括口头和书面语言。
- 多模态情感分析: 作为泛指语言的术语,在机器学习领域中,术语 "language" 通常指的是文本句子,即书面或书写形式的语言。当涉及到包括说话声音时,更常使用术语 "speech" 或 "audio" 来表示口头语言的形式。语音识别和语音处理是涉及声音信号的子领域,而自然语言处理(NLP)通常专注于处理文本数据。
- Lexical (词汇的), adj:
- 用于描述与词汇(单词和词组)相关的事物。例如,"lexical analysis" 涉及对文本中的词汇进行分析,而 "lexical choice" 可能指选择适当的词汇来表达思想。"lexical" 更侧重于词汇层面,涉及到单词和其特性,而 "textual" 更关注整个文本,包括其结构、语法、主题等
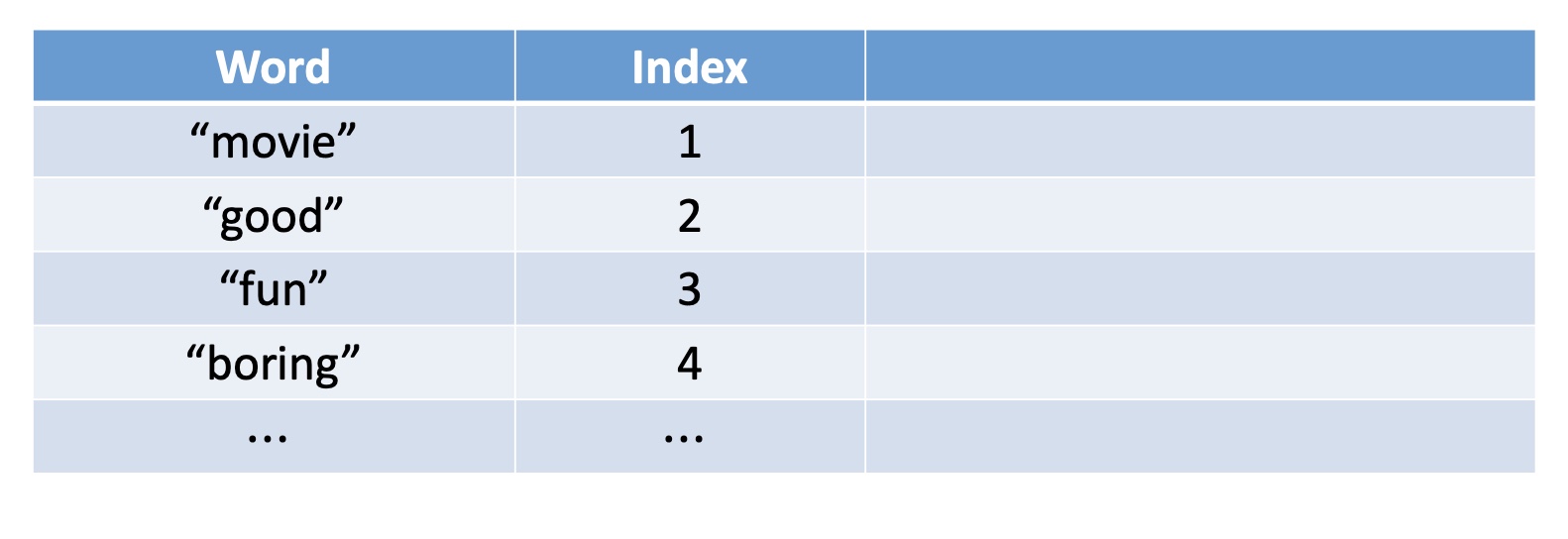
Word Embedding
基本结构其实就是一个嵌入矩阵,且没有bias项。
Word Embedding概念和原理
How to map word to vector?
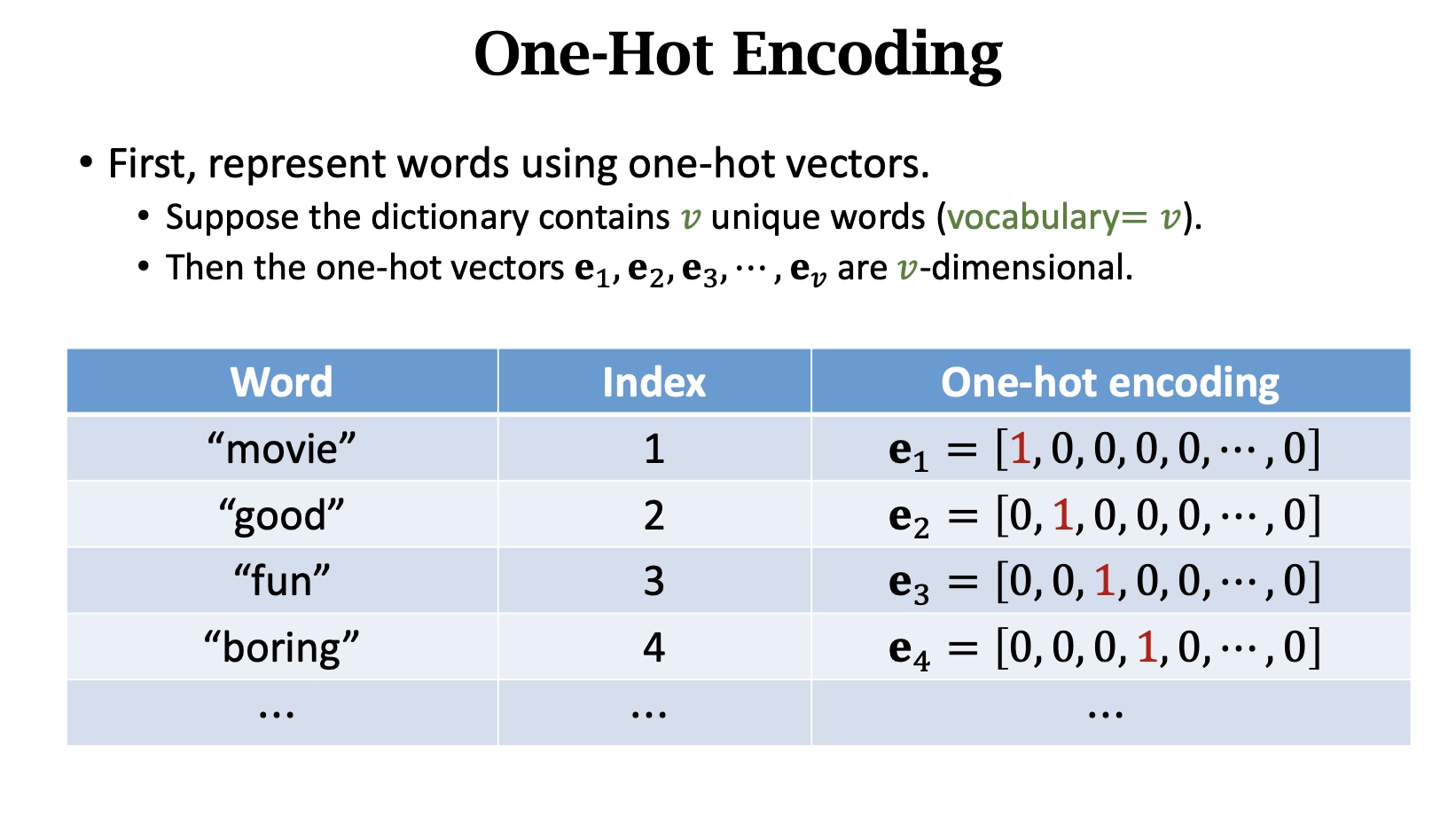
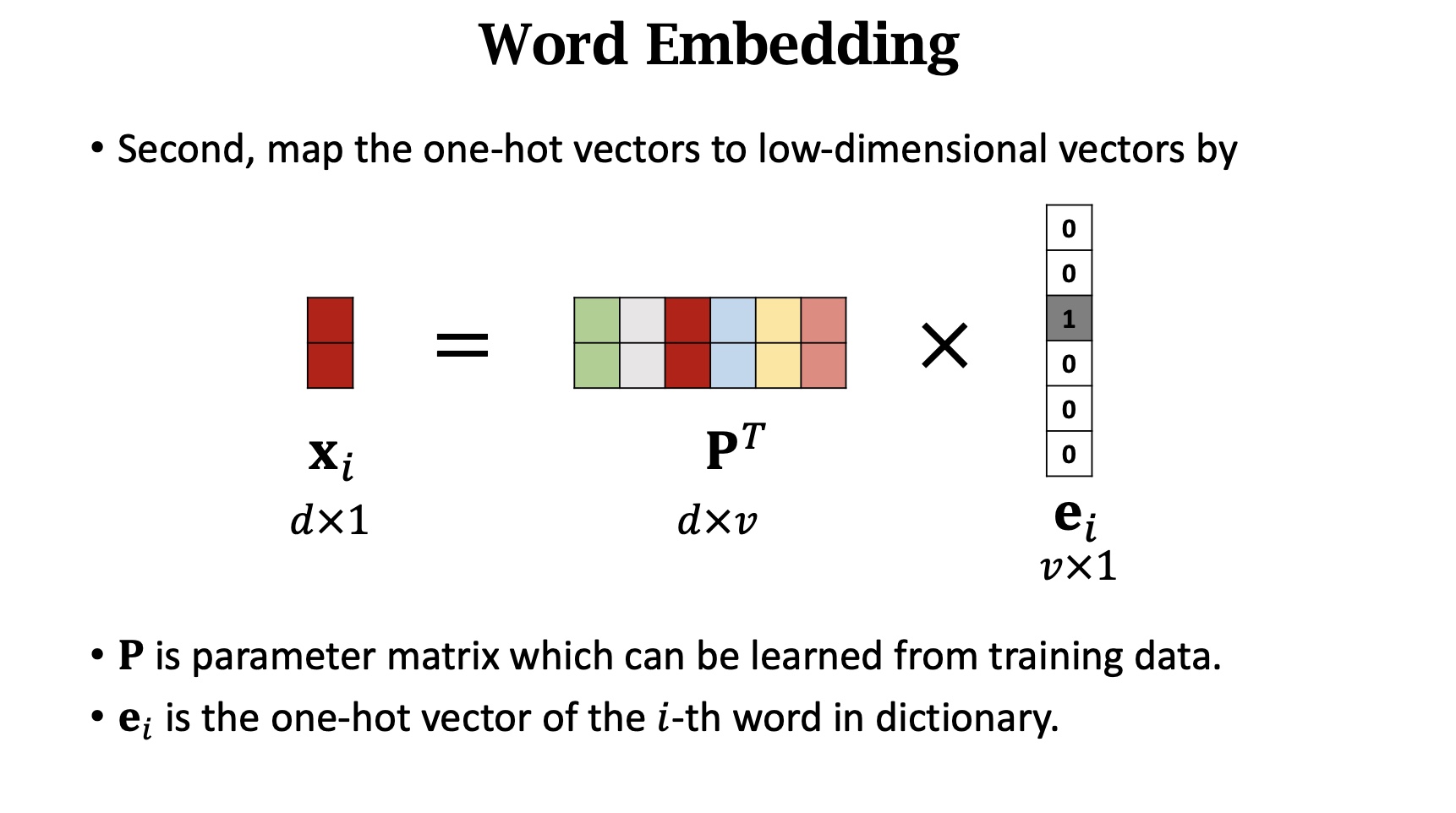
==注意⚠️:P的参数是可以根据训练集学习的==
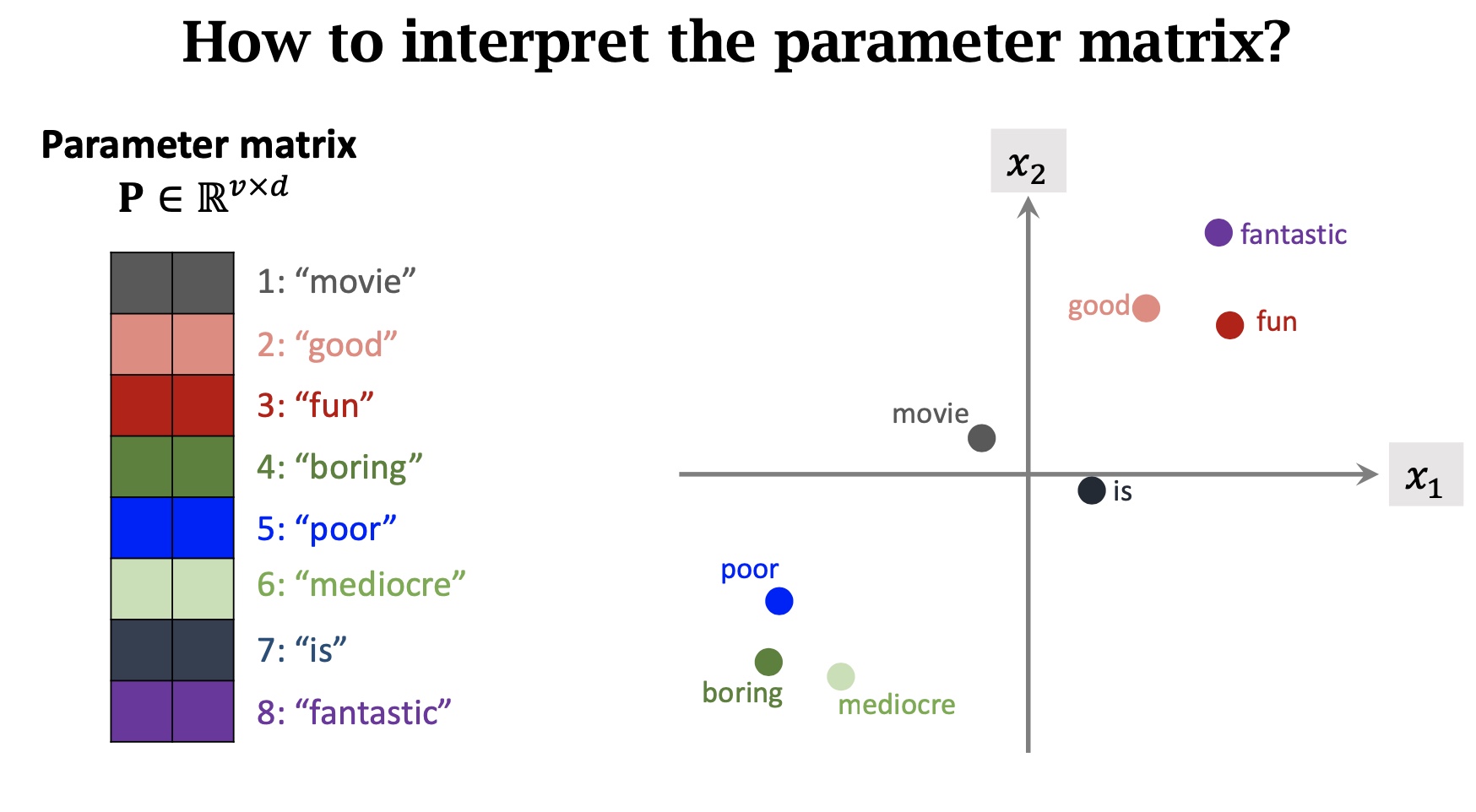
我们希望P对单词的映射是合理的,具有相同的感情色彩的词在嵌入空间中比较接近
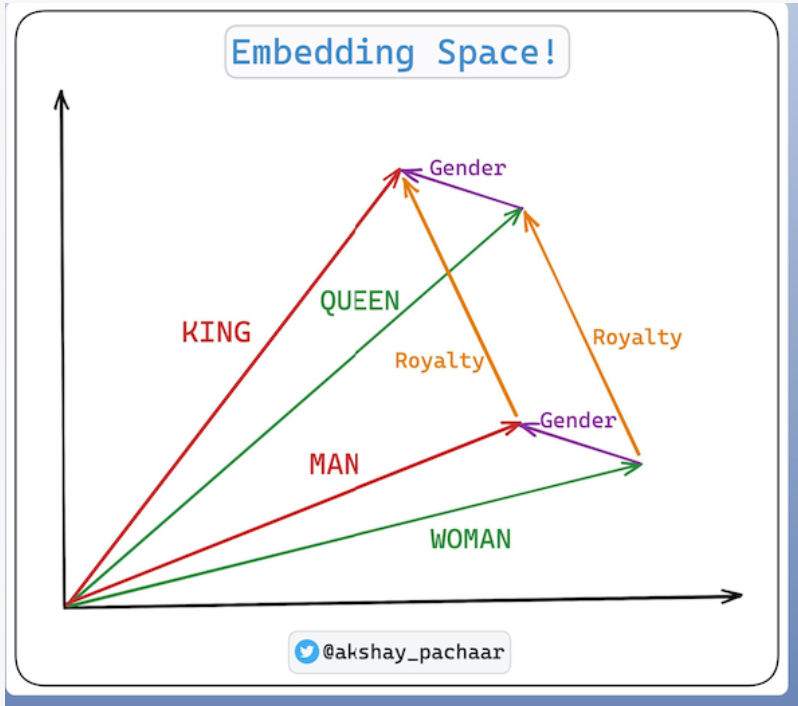
Let’s understand these points with a very famous analogy (you can now refer the image below as you read)!
> King : Queen :: Man : Woman
The word king might be close to the man because they're both male figures. Similarly, the queen might be close to the woman.
But here's the magical part, let’s say we are in the embedding space.
🔹And, if we know the direction and distance from the queen to the king (Gender vector in the image below), we can use the same direction and distance starting from the Woman to find where the Man should be in this embedding space.
🔸Similarly if we know the direction & distance from Man to King (Royalty vector in the image below), we can use the same direction and distance starting from the woman to find where the queen should be in this embedding space.
🔹When we perform these vector arithmetic operations on properly trained embeddings, we get results that capture these relationships.
This makes the embeddings truly magical & powerful!✨
Today we can convert a large corpus of text, documents, images & audio into embeddings.
We have sophisticated databases to store and index embeddings known as vector data bases.
With these databases, we can efficiently perform various operations on the embeddings and build powerful systems on top of them.
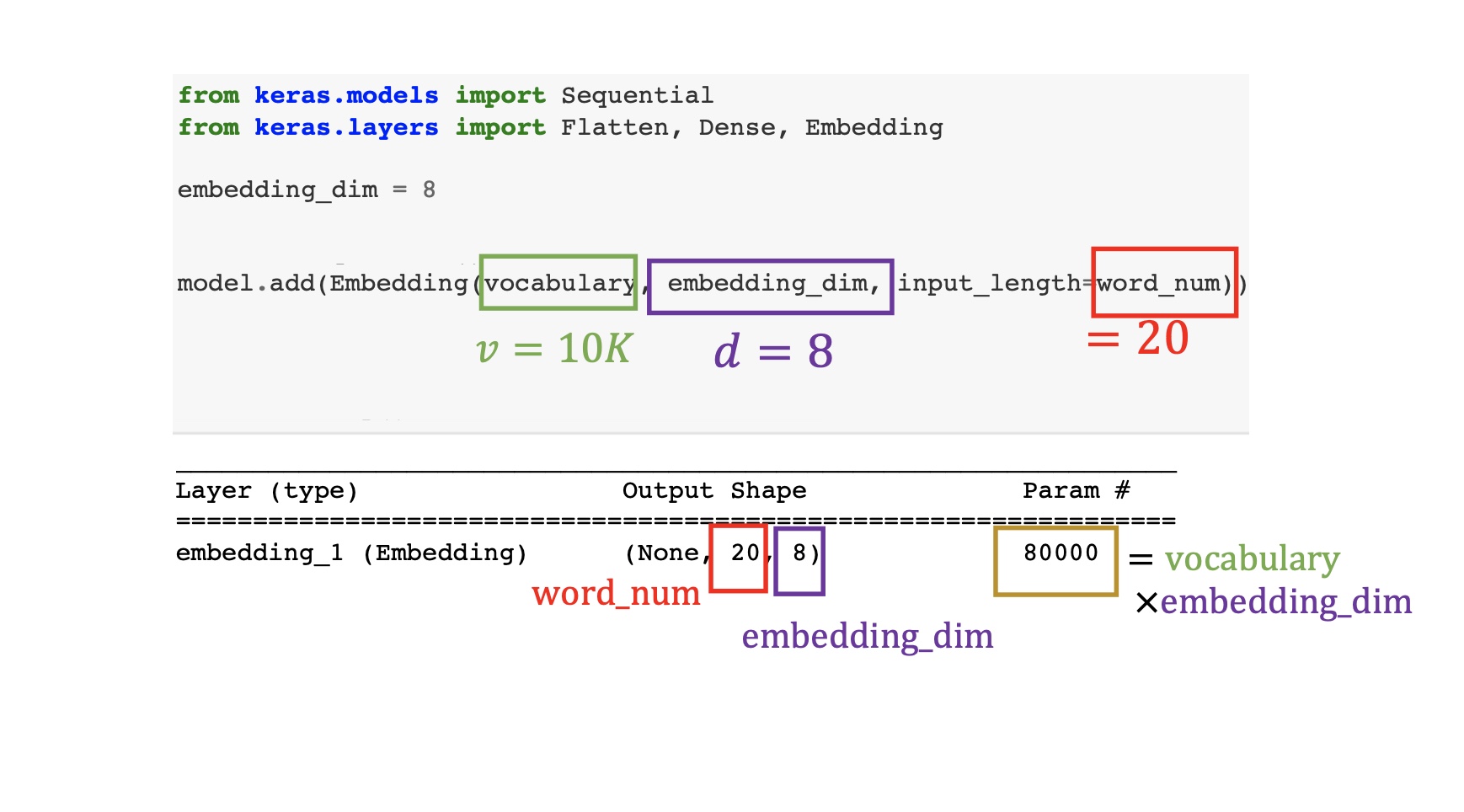
下面这个例子中的Embedding层可学习的参数是10K*8=8万,这里限定了每句话最多20个单词。Embedding的作用就是把这v=10K个单词映射到d=8纬度
nn.Embedding与nn.Linear的计算区别
nn.Embedding学习、理解与nn.Linear区别 - 知乎
nn.Embedding()层其实是一个简单的查找表(Look-Up
Table),将索引值映射到某个维度的权重矩阵。最常见的就是将某个单词映射成embedding向量。最常见的就是将某个单词映射成embedding向量。nn.Embedding()层是可训练的,随着模型训练让单词更好得进行embedding。代码层次,nn.embedding层输入并不需要one-hot
vector格式,直接输入想得到权重的索引就ok。
nn.Linear与nn.embedding
在权重上是转置关系,操作上nn.Linear
做张量运算,nn.embedding 做的索引
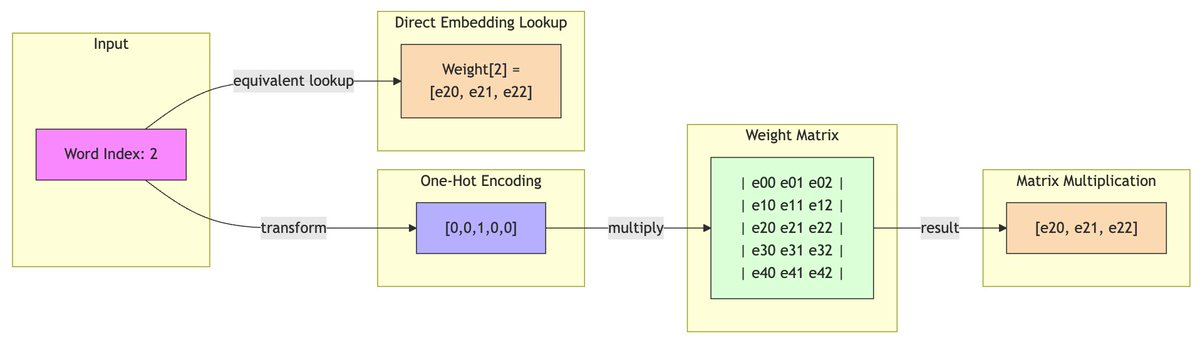
上图粘贴自x.com/adtygan/status/1858588572032659668
Word Embedding和Token Embedding区别
- 词嵌入 (Word Embeddings):是自然语言处理中的一种技术,它将词汇表中的每个单词或短语映射到一个高维空间,其中每个单词都被表示为一个向量。这些向量是根据单词的语境和使月来训练的, 以便语义上相似的单词在向量空间中彼此靠近。
- Token嵌入 (Token Embeddings) :在一些模型中,文本首先被分割成更小的单位称为 tokens, 这些可以是单词、子词单元 (subwords) 或字符。Token嵌入是对这些更细粒度单位的嵌入表示。
Word Embedding 是将单词映射到向量空间的过程,而 Token Embedding 是表示模型输入中的 token 的向量化表示,可以包含单词、子词或字符级别的信息。Word Embedding 是 Token Embedding 的一种形式,它用于将单词表示为向量,而 Token Embedding 则更通用,可以用于表示模型输入中的任何 token。 --ChatGPT
- 实际例子 在 CLIP 模型内,
token_embedding的形状(shape)为 (490408, 512) ,这个矩阵包含了所有可能的文本 token 的嵌入表示,490408 是指 CLIP 模型可以处理的文本标记的数量,这个数字可能包括不仅是完整的单词, 还包括子词单元、特殊字符和可能的标记(如句子开始和结束标记)。具体的词汇表大小可能因模型而异,可以根据具体的实现和训练数据来确定。这使得模型能够处理它没有明确看到过的单词, 通过组合已知的token来理解新词。在传统的自然语言处理中,word embedding 通常对应于一个预定义的词汇表,只包含语料库中的常见词汇。 之后,这些Token嵌入会结合位置嵌入输入到Transformer编码器,最终将文本信息编码成一个向量,以便与图像信息一起输入到 CLIP 模型进行多模态(文本和图像)学习任务。在和图像嵌入比较之前,还会进过一个text_projection映射。
Tokenizer
Tokenization定义
Tokenization:文本数据被分为单词、子词或其他标记(tokens)。这一步称为分词(tokenization),它将文本转换为模型可以理解的离散单位。做了这一步之后,才是把离散的tokens映射到固定维度的embedding。
见上文[[#text embedding, word embedding, sentence embedding, linguistic embedding概念辨析 概念]]
特殊文本标记
为什么需要特殊文本标记
例如encoder将<bos> I love you <eos><pad><pad>编码成向量)
输入:该变量一般取名src。例如可以用0表示句子开始的特殊文本标记(<bos>),1表示句子结束(<eos>),2为填充(<pad>)。填充的目的是为了让不同长度的句子变为同一个长度,这样才可以组成一个batch。
输出:输出这一步推理出的内容,并将此结果作为下一步的输入之一。例如上一轮输出“<bos>我”,通过推理这一轮输出
“<bos>我爱”。输出变量一般取名tgt(target)。
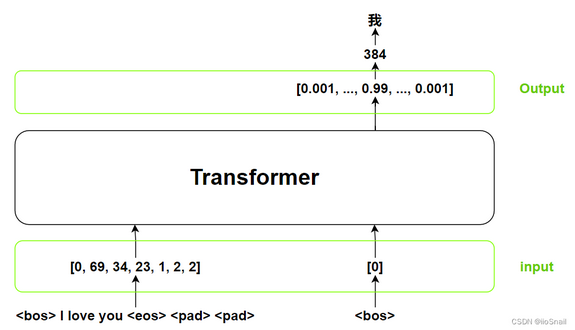
一个机器翻译的例子
Bert中的殊文本标记
special tokens的作用
bert中的special
token到底是怎么发挥作用的 - 知乎 Bert不使用
<bos>(beginning of sequence)和
<eos>(end of sequence)这种特殊标记,Bert中的special
token有
[cls],[sep],[unk],[pad],[mask]。(ChatGPT说对于未登录词(out-of-vocabulary
words),它使用了词汇表中的 [MASK]
标记,通过将这些未登录词替换为 [MASK] 来进行预测。)
注意,
[CLS]、[SEP]、[PAD]、[MASK]在模型的输入端被硬编码,它们作为
token 跟其他文本token一样是固定不变的,但它们的 embedding
表示均是模型参数,会在训练中被学习([PAD]
例外,通常参与不更新)。这些标记在输入文本序列中的作用主要是为了在模型中引入句子级别的信息,以及在预训练时执行各种自监督任务。
[CLS]通常用于表示整个输入句子的语义。[SEP]用于分隔两个句子,对于单个句子的输入也会在句末添加[SEP]。[PAD]用于填充变长序列,使所有输入的长度相同,以便进行批处理。[MASK]用于在预训练时替代一些标记,让模型尝试预测这些被掩盖的标记。
关于用[CLS]做句子的表示
[!caution] 不可学习的[CLS]位本身没有语义,但是经过12层Transformer Layers,通过attention汇聚了所有词的信息。 BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。 为什么选它呢,因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。 具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层,每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。 而[CLS]位本身没有语义,经过12层,得到的是attention后所有词的加权平均,相比其他正常词,可以更好的表征句子语义。 当然,也可以通过对最后一层所有词的embedding做pooling去表征句子语义。 --https://zhuanlan.zhihu.com/p/360343071
用哪个特殊标记做下游任务影响不大
还有一个观点,要用[cls]去做下游句子分类任务的fine-tune才有意义,反正最后根据下游任务finetune之后,bert的参数就会发生一定的变化使得[cls]处得到的hidden state包含句子的表征信息,换句话说,你用别的token的last hidden state来做finetune也没问题。在bert as service中也提到了这个问题以及作者的回答:
Q: Why not use the hidden state of the first token as default strategy, i.e. the
[CLS]?
A: Because a pre-trained model is not fine-tuned on any downstream tasks yet. In this case, the hidden state of[CLS]is not a good sentence representation. If later you fine-tune the model, you may use[CLS]as well.
[cls]加不加没啥太大区别(从keras的mlm的官方的实现来看也可以看到,作者从头训练了一个MLM的bert model,压根就没有把[cls]这个special token加到词表里。)。无论是预训练mlm任务还是句子分类这样的下游任务,完全可以舍弃cls,只不过huggingface以及后续不少开源的model的语料训练的时候大家都模仿了最早的bert往里面加[cls]。
而预训练的模型的输入本身已经将[cls]+句子,这样的输入形式学习到模型的权重中去了(导致[cls]这个token在训练的过程中也被编码了某些知识)。如果你后续finetune的时候不这么做,[cls]+句子A和直接使用句子A分别作为输入来finetune下游的文本分类任务之类的,可能舍弃了[cls]就浪费了一部分信息,效果和保持原始输入形式的效果就会有一些差别。
总结:不是因为special token有特殊意义我们才要刻意地使用special token,而是==因为开源地预训练模型是在这样地输入形式上训练地,所以我们使用地时候也要尊崇其语料地形式==对新语料进行改造,换句话说,如果你有能力自己预训练一个新的model,special token,例如[pad],[mask],[unk]想换成什么都行,而[cls],[seq]不加都可以,或者某些开源的预训练模型里也没有[cls],[seq]之类的奇怪的token,那么就完全不需要加。
[CLS]在NLP与CV模型中的差异
简言之,NLP 中 [CLS] 是“单词表里的一个 token embedding”;ViT 中 [CLS] 是“一个独立的、可学习的全局向量参数”。
| 对比项 | NLP(BERT、LLM) | CV(ViT) |
|---|---|---|
| 来源 | 词表中的一个特殊 token | 独立声明的 learnable parameter |
| 表示方式 | Embedding 矩阵 E 的一行 | 单独的向量参数 \(\text{nn.Parameter}\) |
| 是否可训练 | ✔ 可训练(属于 embedding 参数) | ✔ 可训练(独立参数) |
| 训练更新方式 | 与所有 token embedding 一起,更新稀疏 | 独立向量,梯度更新更直接,梯度密集 |
| 初始化方式 | 随 embedding 初始化(随机/预训练) | 通常用零向量或正态随机初始化 |
| 输入形式 | 拼接在 token 序列最前 | 拼接在 patch embedding 最前 |
| 语义作用 | 汇总整个文本语义 → 用于分类/池化 | 汇总整个图像语义 → 类似 global query |
| 实现方式 | embedding[CLS_id] | nn.Parameter(cls_token) |
| 与其余 token 的关系 | 是token embedding的一部分 | 性质不同于 patch embedding(后者来自线性投影) |
类似的,NLP 中的 [MASK] 是词表中的一个 token,对应 embedding 矩阵的一行。而Masked ViT 中的 mask token 是独立的 learnable 向量,不属于词表,有的架构甚至 encoder 完全不使用 mask token(如 MAE),只在 decoder 阶段填补缺失位置(learnable patch-level placeholder)。
SimpleTokenizer
CLIP用的就是这个,byte pair encoding(BPE)分词器,阿里的千问(QWEN)大模型也用的这个
构建BPE分词
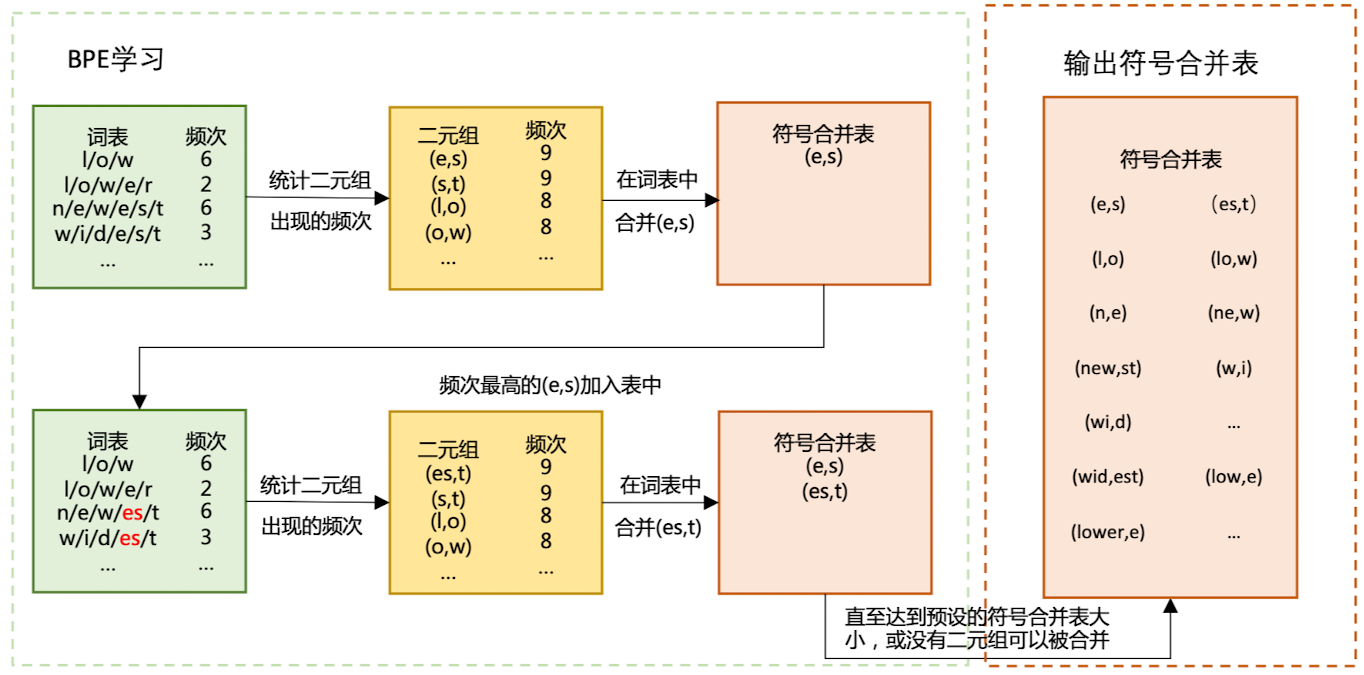
对于多语种,实际使用的是BBPE(Byte-level BPE),略。
使用
摘录自 SimpleTokenizer - 哈哈哈喽喽喽 - 博客园 - 每个单词映射成一个整形,映射表的构成由256个Ascii码映射+bpe常见的字符组合统计包bpe_simple_vocab_16e6.txt.gz(是字符组合的列表,列表先后顺序表示字符组合的频次),然后由总的list和位置构成dict - 映射过程是,比如需要映射bicycle,先将bicycle拆成字符'b','i','c','y','c','l','e',然后相邻字符组合'bi','ic','cy','yc','cl','le',然后找出这些个组合在bpe_simple_vocab_16e6.txt.gz出现位置最靠前的组合(越靠前则频次越高),比如'ic'最高,在字符列表变成'b','ic','y','c','l','e',重复上述过程,直到组合在bpe_simple_vocab_16e6.txt.gz找不到,然后返回组合最终的位置标号,比如最终组合为'bicy', 'cle',即'bicycle'在bpe_simple_vocab_16e6.txt.gz不存在,则返回'bicy'和 'cle'在步骤1中的位置作为最终的tokenizer的结果
一个分词例子
BERT实战——基于Keras
- 那少年和狗 - 博客园 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25from keras_bert import Tokenizer
#字典
token_dict = {
'[CLS]': 0,
'[SEP]': 1,
'un': 2,
'##aff': 3,
'##able': 4,
'[UNK]': 5,
}
tokenizer = Tokenizer(token_dict)
# 拆分单词实例
print(tokenizer.tokenize('unaffable'))
# ['[CLS]', 'un', '##aff', '##able', '[SEP]']
# indices是字对应索引
# segments表示索引对应位置上的字属于第一句话还是第二句话
# 这里只有一句话 unaffable,所以segments都是0
indices, segments = tokenizer.encode('unaffable')
print(indices)
# [0, 2, 3, 4, 1]
print(segments)
# [0, 0, 0, 0, 0]
Tokenizer API in Transformer
摘录自3-3 Transformers Tokenizer API 的使用 - 知乎
我们可以发现,tokenizer API帮我们处理了所有: -
对文本进行特殊字符的添加,例如[CLS]、[UNK]和[SEP]
- padding,batch内每个输入的 vector 都具有相同的长度,需要搭配attention
mask使用,见另一笔记内容 [[Transformer/1 - Transformer基本结构#Masked
Self-Attention|Masked Self-Attention]] -
truncation,每个预训练的语言模型在模型定义的时候,都限定了最长的输入长度
- encoding (tokenize,convert_tokens_to_ids) - 转化为tensor -
输出model 需要的attention mask
1 | import torch |
Tokenizer API in Hugging Face
Hugging Face对其库中分词过程中涉及组件的描述:NLP之分词器——tokenizers()详解 - 知乎 搭建自己的分词器。虽然现有的子词分词器已经非常好用,但是在某些特定的场景中,如法律和医学文本中,通常存在一些常用的==专业术语==,而且这些术语非常重要,值得拥有自己的词条。
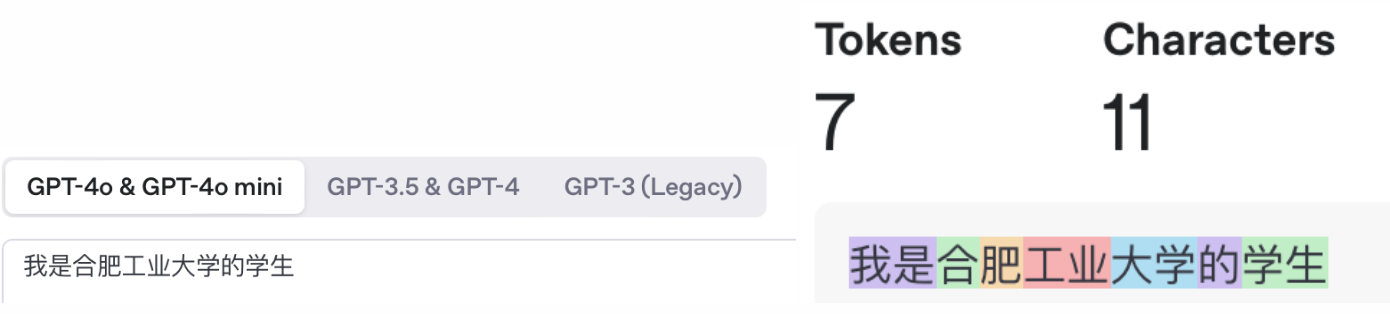
OpenAI的Tokenizer
OpenAI Platform,对于英文大约4个字符一个token。
如何构建支持中文的Tokenizer
以 LLaMA 的中文支持为例,其原始词表大小为 32K,主要基于英文语料训练,仅包含不到 1000 个中文字符。这导致其在处理中文文本时存在以下两个主要问题:
- 大量汉字未直接收录于词表中,需依赖多个字节级 token(通常为 2~3 个)组合表示一个完整汉字。该回退机制显著增加了序列长度,降低了模型对中文的处理效率。
- 字节级 token 并非专为表示汉字设计,它们在 UTF-8 编码下同时用于表示其他字符,难以学习到稳定、有效的汉字语义表示。
为提升模型的中文处理能力,可通过扩展 LLaMA 的 tokenizer 来引入额外的中文词表。例如,先使用结巴分词(jieba)对中文文本进行分词,再将中文词表与原始英文词表合并,构建新的 tokenizer,并对模型进行相应的适配或微调(例如新单词的Embedding)。
声音信号处理基础
简言之,如果对声音这种一维时序信号做时频域变换,转换成类似梅尔频谱图,那么声音模态也能当作常规的图像来处理分析。当然,也有用1D卷积等作为Tokenizer来处理一维时序信号(其他生理信号,序列数据同样处理),从而转化成深度模型(例如Transformer)能接受的token sequences。本质上就是把原始输入映射成一串连续数值的vector序列,再扔给深度网络建模分析。
术语辨析
acoustic, vocal, acoustics, audio,speech单词辨析
- Sound = 总体的“声音现象”。
- Acoustics = 声学/音效(研究 sound 的科学,或环境特性)。
- Audio = 工程角度的“音频信号/设备”。
- Voice = 个体的人声(嗓音,声音产物)。
- Vocal = 发声/唱歌(过程/属性)。
- Speech = 有语言内容的说话(语言层面)。
类比记忆: - light(光) vs optics(光学) - sound(声音) vs acoustics(声学)
Sound (声音) 是最大的集合。它包含了所有能被听到的现象,即通过介质(如空气)传播的振动。这包括了世界万物发出的声音:汽车喇叭声、狗叫声、小提琴声,以及所有人类发出的声音。 人声 (Vocal Sound) 这个范畴把范围缩小到仅由人类发声器官(喉、声带等)产生的声音。包括语言性的(说话)和非语言性的(笑、哭、尖叫、咳嗽、叹息)。 语音 (Speech) 是人声 (Vocal Sound)的一个子集。这是这个链条中最具体的类别,它特指那些为了传递语言信息而按照特定语言规则组织起来的人声。
声学 (Acoustics) 是研究所有 声音 (Sound) 的科学。 音频 (Audio) 是任何 声音 (Sound) 的数字化/电子化格式,audio file 的内容可能是 speech、music (音乐) 或 environmental noise (环境噪声)。
[!example] 一个词汇辨析综合应用例子 In the domain of Multimodal Speech Emotion Recognition, we process the audio signal capturing a speaker's voice. This involves performing acoustic analysis on the rich vocal expressions within the signal to extract features that characterize the emotional content. The entire methodology is grounded in the sciences of phonetics and acoustics.
pitch和tone的区别
- Pitch(音高):是声音的物理-/感知属性(高低)。
- Tone/Intonation(声调/语调):语言系统中由 pitch 形成的“功能单位”,把 pitch 轨迹模式化**,用于区分词义或表达语气。
| 概念 | 定义 | 属性 | 举例 |
|---|---|---|---|
| Pitch(音高) | 声带振动频率 F0 的感知结果(高低) | 物理 & 听觉属性(连续变化) | 男声约 100Hz、女声约 200Hz;同一个人可以高声或低声说“啊” |
| Tone(声调) | 语言系统中用 Pitch 高低变化来区别词义的模式 | 离散化的音高模式,词汇功能 | 汉语“四声”:mā(妈 --从高到高)、má(麻 --中到高)、mǎ(马 --先中到低,再升高)、mà(骂 --高到低 ) |
| Intonation(语调) | 在句子层面利用 Pitch 变化表达语气、情感、语法关系 | 语用功能 | 英语:陈述句结尾下降,疑问句结尾上扬 |
音素
音素 = 区分词义的最小发音单位
| 语言 | 音素构成 | 音高作用 |
|---|---|---|
| 中文 | 声母 + 韵母 + 声调 | 声调是音素的一部分,用来区分词义(妈/马/骂) |
| 英文 | 辅音 + 元音 | 音高只用于语调,不影响词义(cat 升调只是问句,不是新词) |
注意:英语中的语调(音高变化)不是音素,例如表中的例子cat升调,但不会改变词义。
韵律、音色、音质
韵律 (Prosody)、音色 (Timbre) 和 音质 (Voice Quality)被视为三个正交(orthogonal) 且相互独立的维度来描述声音特性。它们从不同的层面、在不同的时间尺度上刻画了声音的本质。
为了更形象地理解,我们可以做一个类比:如果把一段话语比作一首音乐:
- 韵律
(描述“说什么”的方式)就像是这首音乐的旋律和节奏。它决定了乐句的起伏、快慢和轻重缓急。韵律是超音段
(suprasegmental)
的,它的作用范围超越了单个音素,延伸到音节、词语和整个句子,承载了大量的语义和情感信息。
- 韵律的核心声学特征:
- 基频轮廓 (F0 Contour):构成语调 (Intonation)。
- 音强轮廓 (Intensity Contour):构成重音 (Stress)。
- 音长和停顿 (Duration & Pauses):构成节奏 (Rhythm)。
- 音色 (描述“谁在说”的身份)
就像是演奏这首音乐的乐器。是小提琴、钢琴还是萨克斯风?它们演奏相同的旋律,但听起来完全不同。音色是声音的“指纹”,它由发声体(如声带)和共鸣腔(如声道)的物理结构决定。
- 音色的核心声学特征:
- 频谱包络 (Spectral Envelope):由共振峰 (Formants) 决定,反映了声道的形状。
- 谐波结构 (Harmonic Structure):各次谐波的相对能量分布。
- 音色的核心声学特征:
- 音质 (描述“怎么说”的状态)
就像是这件乐器的物理状态和演奏技巧。这把小提琴的琴弦是崭新的还是老旧的?演奏者的弓法是平滑流畅还是带有摩擦的沙哑感?音质描述了声带振动的具体模式和气流的控制方式,反映了声音的“质地”。
- 音质的核心声学特征:
- 抖动 (Jitter):基频的周期性扰动。
- 颤动 (Shimmer):振幅的周期性扰动。
- 谐波噪声比 (HNR):声音中周期性成分与噪声成分的比例。
- 音质的核心声学特征:
在理论上,这三个维度是独立的。例如,同一个人(音色固定)可以用不同的语调(韵律变化)说出清晰(音质好)或沙哑(音质差)的一句话。但在实际发声中,它们会相互影响。比如,当一个人激动地大喊时,他的韵律(音高和音强升高)、音色(共振峰可能变化)和音质(可能变得紧张或粗糙)都会发生改变。
声学知识
音频帧
• 在音频信号处理中,音频“帧”通常指的是在特定时间窗内的音频数据。每一帧包含一定时长的连续音频信号。 • 举个例子,如果音频信号被切分成25毫秒长的帧,每一帧就包含该时间段内的音频数据。这些音频数据会被用来进行特征提取(如计算频谱、梅尔频谱图等),从而反映出该时段的频率特征。因为语音信号在这一时间范围内可以近似为平稳信号。
• 帧的大小通常是由时间窗的长度(如25ms、50ms等)决定的,而帧移(frame shift)决定了帧之间的重叠程度。例如,帧移为10ms时,相邻两帧有15ms的重叠部分,以避免切分导致的信息丢失,并确保相邻帧的平滑过渡。
那么为什么不用每个声音采样点直接作为最小单元? 单独的采样点无法捕捉音频的频率信息,而频率信息对于语音理解是至关重要的。例如: • 人的语音包含许多不同频率的振动(基频、共振峰等),这些频率分量是语音识别和建模的重要依据。 • 如果只用采样点,无法直接看到“哪些频率分量在什么时间出现”,因此难以提取有意义的语音特征。 音频帧通过聚合多个采样点,提供了一段时间内的频率和振幅分布
分贝的计算
分贝(dB)是对数单位,用于表示信号的强度或能量相对参考值的比值。对数变换使得信号的动态范围得到压缩,便于分析和可视化。负数dB表示信号的强度低于参考值,例如,当信号的幅度小于参考幅度时,计算出的分贝值为负数。在音频信号处理中,选择合适的参考值是计算分贝时非常重要的一步。通常会选择RMS(均方根)幅度或最大幅度作为参考值。 计算分贝时,具体公式取决于信号的性质:
- 对于功率信号,使用10 log公式:\(\text{dB} = 10 \log_{10} \left( \frac{P}{P_{\text{ref}}} \right)\),其中P是信号的功率,P_ref是参考功率;
- 对于幅度信号,使用20 log公式:\(\text{dB} = 20 \log_{10} \left( \frac{A}{A_{\text{ref}}} \right)\),其中A是信号的幅度(如电压、振幅),A_ref是参考幅度。备注:由于功率与幅度的平方成正比(\(P \propto A^2\)),因此在计算幅度的分贝时使用20倍的对数。 在音频信号处理中,通常使用20 log来表示信号的幅度分贝。分贝单位能够更好地适应人类对声音强度的感知,而不是线性的绝度振幅,特别是在处理动态范围很大的音频信号时。
声音信号分析核心概念
--Gemini 2.5
语音信号分析核心概念总结 (补充完善版)
1. 声音信号的三个基本物理维度
- 幅度/振幅 (Amplitude):描述空气压力变化的强度,直接对应于我们主观感知的 响度 (Loudness)。振幅越大,声音听起来越响。对于单声道信号,一个时间点只有一个振幅值。
- 频率 (Frequency):指声波振动的速度,单位是赫兹 (Hz)。它是一个客观的物理量。频率决定了我们主观感知的 音高 (Pitch)。
- 时长 (Duration):指声音持续的时间。
2. 音高 (Pitch) vs. 基频 (Fundamental Frequency, F0)
- 基频 (F0):对于周期性或准周期性声音(如元音),其波形重复出现的最慢频率,即最低频率成分。它是由声带的振动频率决定的物理量。
- 音高 (Pitch):人耳对声音高低的主观感知。音高主要由基频决定,但也会受到响度等其他因素的轻微影响。在语音分析中,我们通常将两者近似等同,通过计算F0来量化音高。
3. 频谱 (Spectrum) 与音色 (Timbre)
一个复杂的声音(如人声)并非由单一频率构成,而是由多个不同频率的正弦波叠加而成。将这些频率成分展开,就能得到声音的频谱。
基波 (Fundamental Wave):构成声音的频率最低的那个正弦波,其频率就是 基频 (F0)。它通常也被称为 一次谐波。
- 特别注意:这里的“一次”指的是基频的 1倍,是一个序号或倍数,不代表频率就是1Hz。
- 例如:一个成年男性的基频 (F0) 可能在 120 Hz
左右。那么:
- 他的 基波(一次谐波) 频率就是 1×120 Hz=120 Hz。
- 二次谐波 的频率就是 2×120 Hz=240 Hz。
- 三次谐波 的频率就是 3×120 Hz=360 Hz,以此类推。
谐波 (Harmonics):频率是基频 (F0) 整数倍 (2F0,3F0,4F0,...) 的一系列正弦波。
音色 (Timbre):区别不同声音的关键特征(例如,小提琴和钢琴以相同的音高和响度演奏同一个音符,我们依然能区分它们)。音色主要由两个因素决定:
- 谐波的相对强度:谐波与基波的能量分布比例。
- 共振峰 (Formants)。
4. 共振峰 (Formants) - 音色的塑造者
定义:当声带产生的原始声音(包含基频和各次谐波)经过声道(咽喉、口腔、鼻腔)时,特定频率的能量会被放大和增强(能量集中区域),形成能量的峰值,这些峰值就是共振峰。在同一个时间点,一个声音可以包含多个共振峰,因此有多个共振峰频率。
成因:共振峰的频率位置由 声道的形状 决定。当我们说话时,舌头、嘴唇、下巴等发音器官的运动会不断改变声道的形状,从而导致共振峰的频率实时变化。
作用:共振峰是决定 音色,特别是 元音 (Vowel) 音色的关键。不同的元音(如 a, i, u)就是通过舌头和嘴唇的位置变化,塑造出不同的共振峰结构,从而被我们区分开来。例如,元音 /i/(“衣”)的特点是第一共振峰 (F1) 频率很低,而第二共振峰 (F2) 频率很高。这就是为什么声谱图上,共振峰通常表现为多条平行的、明亮的能量带,而不是一条单一的线。每条明亮的带都代表一个共振峰。
5. 幅度包络 (Amplitude Envelope) - 声音的动态轮廓
- 定义:描述声音 响度
随时间变化的轮廓线。一个典型的声音事件通常包含四个阶段:
- 起音 (Attack):响度从零迅速上升到峰值。
- 衰减 (Decay):从峰值略微下降。
- 延持 (Sustain):响度在一个相对稳定的水平上保持一段时间。
- 释音 (Release):响度逐渐衰减至零。
- 作用:包络线同样是影响 音色 的重要因素。它定义了声音的“生命周期”或动态特性。例如,敲击乐器(如鼓)和拉弦乐器(如小提琴)的包络线就截然不同。
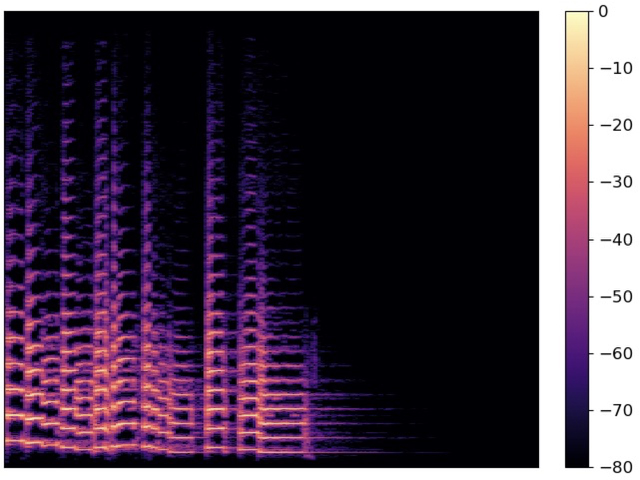
6. 声谱图 (Spectrogram) 中的视觉特征解读
声谱图是一个三维图,它同时展示了 时间
(x轴)、频率 (y轴) 和 能量/幅度
(颜色深浅或亮度)。
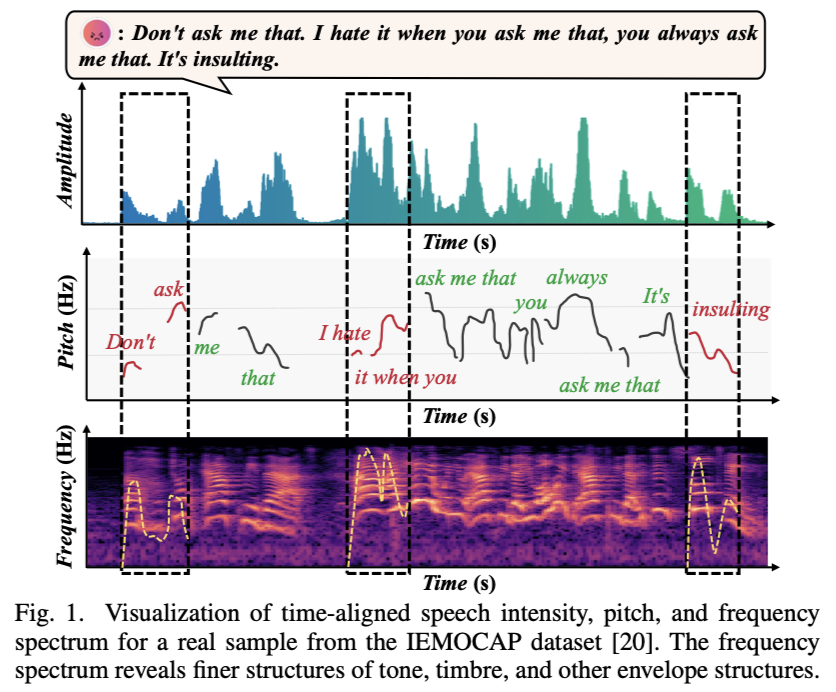
第三行的声谱图中黄色虚线可能是共振峰的轨迹(也可能作者错了。共振峰的绘制不是取平均值,而是通过在每个时间点上找到多个能量峰值。算法将这些峰值按频率高低排序,并分别命名为 F1(频率最低)、F2(频率次低) 等,然后将同序号的峰值点连接成多条平滑轨迹,间一个例子提取时长和共振峰的具体例子-CSDN博客)。该图片摘录自Temporal-Frequency State Space Duality: An Efficient Paradigm for Speech Emotion Recognition,ICASSP 2025
- 垂直条纹 (Vertical Stripes):在浊音(声带振动)区域,可以看到密集的垂直细条纹。每一条细纹大致对应于声带的一次振动,条纹的疏密程度反映了 基频 (F0) 的高低。条纹越密,基频越高,音高也越高。
- 水平谐波带 (Horizontal Harmonic Bands):细看这些垂直条纹,它们在能量强的频率上会连成一片,形成明亮的 水平条带,这就是 谐波。最下面、通常最亮的一条即为 基频 (F0) 的轨迹。
- 垂直条纹的断裂是由浊音和清音的交替引起的,而水平条纹的连续性则是因为声音的频率成分在整个发音过程中都存在。
- 共振峰 (Formants):表现为频率范围内更宽、能量更集中的 亮带。这些亮带的中心频率会随着发音内容的变化而 上下移动。上图注释中提到的“黄色虚线很可能追踪的就是某个共振峰的轨迹”,这个判断是非常正确的,因为共振峰反映了发音器官的运动,是动态变化的。F1(第一共振峰)反映了发音时舌头的高低,而F2(第二共振峰)则反映了舌头的前后位置,两者共同决定了元音的音色。
7. 声谱图中垂直和水平条纹的成因
声谱图中的条纹模式反映了人类发声的两种基本物理机制:
1). 垂直条纹的成因:声带振动
垂直条纹是由声带的周期性振动产生的。在语音学中,声谱图的分析方法是将一个连续的语音信号切分成非常短的、连续的时间片段。在每一个时间片段内,如果说话者的声带正在快速、规律地振动,就会在频谱上产生一系列离散的能量峰值,这些峰值对应于基频和其谐波。在声谱图上,这些离散的能量峰值在垂直方向上被描绘为一条细线。
因此,每一条垂直细线都代表了声带的一次完整振动周期。这种条纹只出现在浊音(如元音和浊辅音)中。而那些发音时声带不振动的辅音,即清辅音(例如 /p/, /t/, /k/, /s/, /f/),则不会产生垂直条纹。它们的声谱图通常是一片模糊或高频的噪声区域。条纹越密,代表声带振动越快,声音的音高越高。
2). 水平条纹的成因:频率成分
水平条纹是由声音的频率成分(即谐波和共振峰)产生的。无论声带是否振动,声音都有其独特的频率组成。这些在特定频率上的能量峰值在声谱图上形成了明亮的水平条带。这些条带反映了声音在不同频率上的能量分布。
这些水平条纹贯穿整个语音,因为声音的频率组成始终存在。它们主要决定了声音的音色。例如,共振峰的频率起伏变化反映了发音器官(如舌头和嘴唇)的运动,这使得我们可以区分不同的元音。
3). 在人类语音的声谱图中,水平条纹通常是连续的,而垂直条纹则经常是断裂的
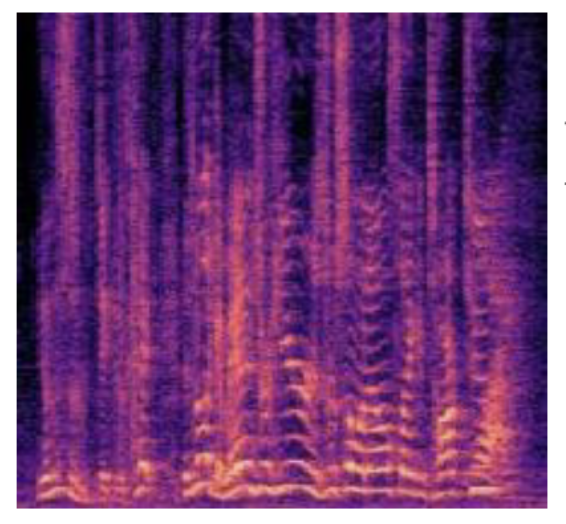 这个现象完美地反映了人类发声的两种基本模式:浊音和清音。
这个现象完美地反映了人类发声的两种基本模式:浊音和清音。
- 垂直条纹代表声带的振动。这些条纹只在发出浊音(如元音 a, e, i, o, u,以及辅音 m, n, l)时出现。当声带不振动,发出清音(如辅音 p, t, k, s, f)时,垂直条纹就会中断,声谱图上呈现为一片不规则的能量。因此,垂直条纹在整个语音流中是断断续续出现的。
- 水平条纹代表声音的频率成分。无论声带是否振动,声音总是由不同频率的能量组成。这些频率成分(谐波和共振峰)在整个语音过程中持续存在,所以它们在声谱图上形成了连续的水平轨迹。
8. 总结与对比
| 概念 | 决定因素 | 听觉感知 | 在声谱图中的体现 |
|---|---|---|---|
| 基频 (F0) | 声带振动快慢 | 音高 (Pitch) | 最低的一条谐波亮带;或垂直条纹的疏密 |
| 谐波 (Harmonics) | 基频的整数倍 | (与共振峰共同决定) 音色 (Timbre) | 与基频平行的一系列水平亮带 |
| 共振峰 (Formants) | 声道(口腔、舌头等)的形状 | (与谐波共同决定) 音色 (Timbre),尤其是元音 | 宽阔且动态变化的水平能量集中区域 |
| 振幅 (Amplitude) | 气流强度与声门闭合力度 | 响度 (Loudness) | 颜色的深浅或亮度(越亮/颜色越深,能量越强) |
音频模态的主要特征
GPT-4o 从声学角度,音频模态的主要特征可以概括为以下几类:
1.时域特征:描述音频信号在时间维度上的属性。常见特征包括能量 (Energy),过零率(Zero-Crossing Rate,ZCR),音长(Duration)。
2.频域特征:描述音频信号在频率维度上的分布。常见特征包括频谱质心(Spectral Centroid),频谱带宽(Spectral Bandwidth),谱摘 (Spectral Entropy)。
3.时频特征:描述信号在时间和频率上的联合变化。常见特征包括短时傅里叶变换(STFT),Mel频率倒谱系数(MFCC),线性预测倒谱系数(LPCC)。
4.谱特征:描述频谱形状的具体属性,反映声道结构和发声机制。从本质上看,谱特征属于频域特征的一个子集。常见特征包括共振峰(Formants),谱包络(Spectral
Envelope,对应也有时间包络),谐波与非谐波比(HNR)。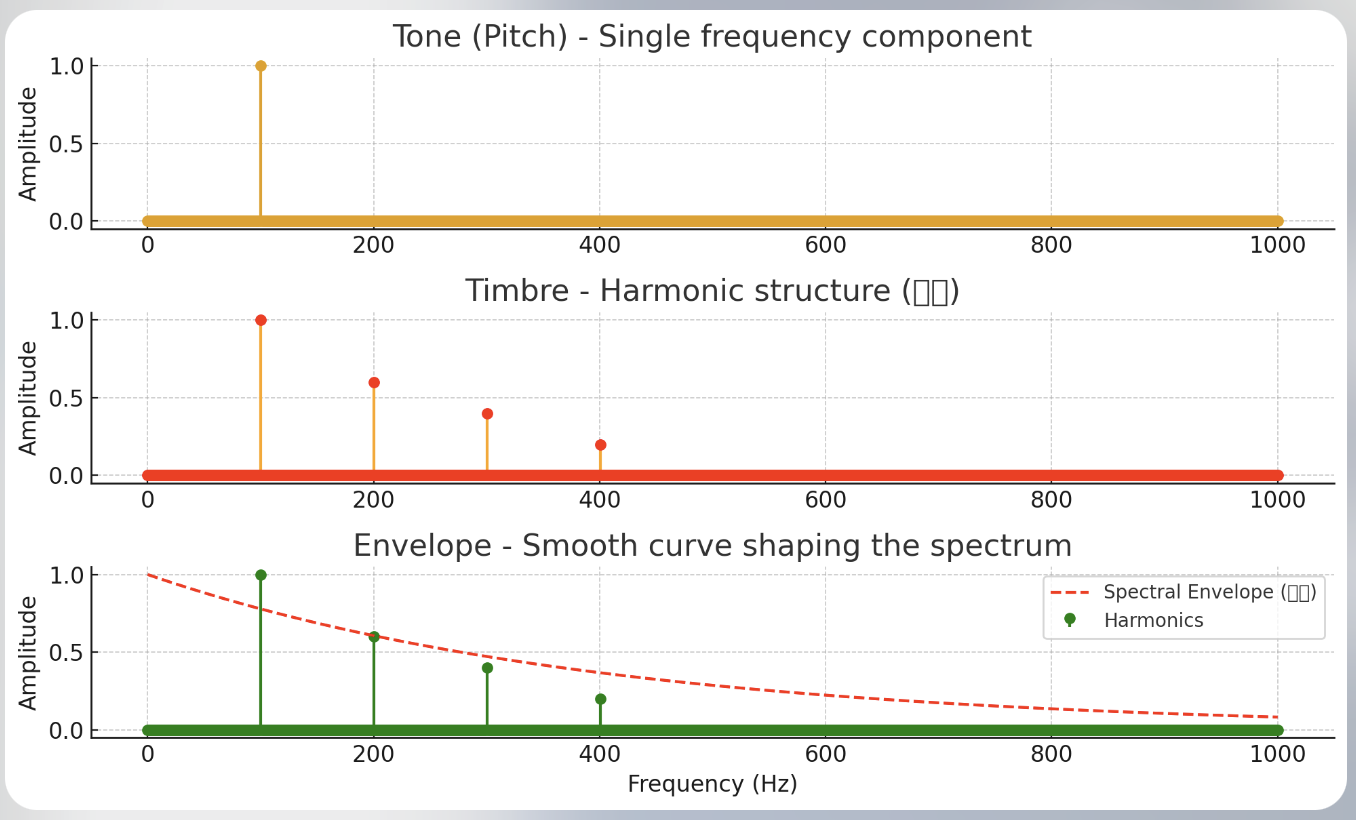
5.韵律特征:描述语音的超音段特性,与情感,语调密切相关。常见特征包括基频(FO),音强(Intensity),音长(Duration),语速 (Speech Rate),节奏性变化。
6.音质特征:描述语音信号的清踝度,纯净度和信号质量。常见特征包括抖动(Jitter),颤动(Shimmer),信噪比(SNR)。
7.动态特征:描述频谱特征或韵律特征的变化趋势和动态模式,常见的有一阶差分(Delta Features), 二阶差分(Delta-Delta Features)
8.音色特征:主要归属于谱特征,但它的表征也会涉及时频特征和韵律特征。研究音色时,应结合谱特征的静态描述(如频谱质心、谱包络)和动态变化(如MFCC及其差分特征)来全面表征音色属性。
频域特性与动态特性的关系
频域特性是可以反映动态变化的,但这种变化通常通过短时分析或时间差分来捕捉。相比之下,时频特性更进一步,将时间和频率的动态关系综合呈现,因此在描述动态变化时,时频特性可能更为直观和全面。 频域特性本质上反映了信号在特定时间窗口内的频率分布情况 静态频域特性:例如单一时刻的谱包络、谱质心,这些特性在短时间内是固定的。 动态频域特性:通过分析这些特性随时间的连续变化(如轨迹、差分等),可以体现信号的动态属性。
对数梅尔频谱图如何计算
--GPT-4o回答
简介
对数梅尔频谱图(Log-Mel Spectrogram)是将音频信号表示为随时间变化的频率能量图的图像表示。其英文术语是 Log-Mel Spectrogram。Log-Mel频谱图是声音信号处理中常用的特征表示方法,广泛应用于语音识别、音乐信息检索等领域。它是通过短时傅立叶变换(STFT)和 Mel 频率滤波得到的,然后对其进行对数变换。 例如,一个处理后的语音声谱图数据也可以表示为一个二维张量,但它的维度有不同的含义:
- 高度(频率轴):代表 梅尔滤波器组(mel-filter banks) 的数量,通常为 40、64 或 128。这决定了我们分析语音频率的精细程度。
- 宽度(时间轴):代表总帧数。这个数字取决于音频的总时长、帧长和帧移。例如,一个 10 秒的音频,帧长 25 毫秒,帧移 10 毫秒,就会有大约 1000 帧,宽度就是 1000。
处理步骤
加载音频文件:使用
librosa库加载音频文件并进行重采样。短时傅立叶变换 (STFT):对音频信号进行 STFT,得到频域表示。
Mel 滤波:将频域表示映射到 Mel 频率尺度。
对数变换:对 Mel 频谱进行对数变换,得到 Log-Mel 频谱图。 ### 计算公式描述过程
短时傅立叶变换 (STFT)
\[ X(t, f) = \sum_{n=0}^{N-1} x[n] \cdot w[n-t] \cdot e^{-j2\pi fn/N} \]
其中,( x[n] ) 为音频信号,( w[n] ) 为窗口函数,( N ) 为 FFT 的大小。 具体来说,窗口函数 w[n]是短时傅立叶变换 (STFT) 中用来处理信号的一段取样窗口。它的作用是在计算傅立叶变换时平滑信号的边缘,减小频谱泄露效应。常见的窗口函数有矩形窗、汉宁窗、汉明窗和黑曼窗等。
- Mel 频率转换
\[ M(f) = 2595 \cdot \log_{10}(1 + f / 700) \]
- Mel 频谱
\[ S_{mel}(t, m) = \sum_{k=0}^{K-1} |X(t, k)|^2 \cdot H_m(k) \]
其中,( H_m(k) ) 为 Mel 滤波器,( K ) 为频谱的频率分辨率。
- 对数变换
\[ \text{Log-Mel}(t, m) = \log(S_{mel}(t, m) + \epsilon) \]
其中,( ) 是一个小常数,用于避免对数零值。
- 时间轴长度的保持 前后时间段的长度保持一致,即如果你计算了3秒钟的音频信号,对应的对数梅尔频谱图也是描述这3秒的频率变化,只不过它被分割成了多个短时窗。在对音频信号进行处理时,通常会将信号划分为多个小的时间窗口或“帧”(frame)。每一帧包含了一定数量的连续采样点。然后,针对每一帧进行频谱分析(如傅里叶变换),从而提取该时间段内的频率特征。 例如,如果原始信号的采样率为16kHz,窗口大小为25ms(也就是一帧),步长为10ms,那么对于3秒钟的信号,经过处理后你会得到大约 (3 / 0.01) = 300 帧。每一帧会在横坐标上表示一个时间点,这个时间点对应的是窗的开始时刻。
代码实现
以下是使用 librosa 库进行 Log-Mel 频谱图计算的 Python
代码示例。补充一句,torchaudio 是 PyTorch
的一个音频处理库,提供了很多音频相关的功能,可以方便地集成到 PyTorch
的深度学习框架中。:
1 | import librosa |
参数具体解释
- sr (sampling rate): 22050
- 这是音频信号的采样率,表示每秒钟采样的次数。22050 Hz 表示每秒钟采样 22050 个点。
- n_fft: 2048
- 这是傅立叶变换的窗口大小,也就是每个窗口包含的采样点数。2048 个采样点表示窗口长度为 2048 个点。
- hop_length: 512
- 这是窗口之间的步长。512 表示每个窗口之间有 512 个点的间隔。换句话说,窗口的重叠部分有 ( n_fft - hop_length = 2048 - 512 = 1536 ) 个点。
- n_mels: 128
- 这是 Mel 频谱图中的 Mel 滤波器组数量。128 表示 Mel 频谱图有 128 个 Mel 频带。
如果需要更底层的控制,可以使用 SoundFile 和
NumPy 来处理音频数据并生成频谱图。以下是一个使用
SoundFile 和 NumPy 生成 Log-Mel
频谱图的示例
1 | import numpy as np |
数据预处理
在输入给用于声音分类的深度网络前,通常需要进行以下数据预处理操作:
归一化:将频谱图的值归一化到某个范围(如 0 到 1 或 -1 到 1),这有助于提高网络的训练稳定性和收敛速度。
1
2
3
4from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
log_mel_spectrogram_normalized = scaler.fit_transform(log_mel_spectrogram)调整维度:如果深度学习模型期望的输入是特定的维度,需要对频谱图进行裁剪或填充,以确保所有输入样本具有相同的形状。
1
2
3
4
5
6
7
8
9import numpy as np
def pad_spectrogram(spectrogram, target_shape):
padded_spectrogram = np.zeros(target_shape)
padded_spectrogram[:spectrogram.shape[0], :spectrogram.shape[1]] = spectrogram
return padded_spectrogram
target_shape = (128, 216) # Example shape
log_mel_spectrogram_padded = pad_spectrogram(log_mel_spectrogram_normalized, target_shape)添加通道维度:如果使用的深度学习框架期望输入具有通道维度(如 CNN),需要增加此维度。
1
log_mel_spectrogram_padded = np.expand_dims(log_mel_spectrogram_padded, axis=-1)
批量处理:处理多个音频文件,并将它们存储在批量数据集中,以便于模型的训练和验证。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import os
def process_audio_files(file_paths):
spectrograms = []
for file_path in file_paths:
audio, sr = librosa.load(file_path, sr=22050)
stft = librosa.stft(audio, n_fft=2048, hop_length=512)
mel_spectrogram = librosa.feature.melspectrogram(S=np.abs(stft)**2, sr=sr, n_mels=128)
log_mel_spectrogram = librosa.power_to_db(mel_spectrogram)
log_mel_spectrogram_normalized = scaler.fit_transform(log_mel_spectrogram)
log_mel_spectrogram_padded = pad_spectrogram(log_mel_spectrogram_normalized, target_shape)
log_mel_spectrogram_padded = np.expand_dims(log_mel_spectrogram_padded, axis=-1)
spectrograms.append(log_mel_spectrogram_padded)
return np.array(spectrograms)
file_paths = ["/path/to/audio1.wav", "/path/to/audio2.wav"] # Example file paths
dataset = process_audio_files(file_paths)
总结
对数梅尔频谱图(Log-Mel Spectrogram)是通过短时傅立叶变换(STFT)将音频信号在时间和频率两个维度上进行表示,展示了随时间变化的不同频率信号的能量分布。在输入给深度网络之前,需要进行归一化、调整维度、添加通道维度等数据预处理操作。通过这些步骤,可以将音频信号转换为适合深度学习模型处理的输入格式,从而进行声音分类等任务。
多模态数据融合
对不同来源的模态数据单独处理好后,便可以选择在早/中/晚期做数据融合。这是另外一个话题了,不再展开。实际项目中也经常用别人现成的各种模态Encoder直接得到token sequences,然后每个模态接一个Projection Layer映射到多模态统一语义空间。这方面的做法繁多,但看到这里你已经有动手处理多模态问题的基础!感谢前人的伟大贡献,让我们能够如此快速轻松地入门。

